
预计阅读时间: 9 分钟
最近来自Google的Yu Zhao向Linux内核提交了一个Patch,修改了内核内存管理模块中的页面置换算法,提出了多级LRU,本文带你了解页面置换算法和多级LRU的优势。
什么是页和页面置换
我们知道,在几乎所有的现代操作系统和处理器上都使用了内存分页机制。某些嵌入式操作系统和特殊情况下,处理器资源很紧张,不需要考虑进程间安全问题,甚至没有线程这一概念时,内存分页也就没有必要了。内存分页是为了虚拟内存机制而提出的,大多数现代操作系统上为了进程间的隔离,每个进程拥有自己独立的地址空间,这就是虚拟内存。虚拟内存需要与物理内存有一个映射,但是问题来了,这个映射表是需要占用内存空间的,尤其是64位处理器上,需要映射的地址空间非常庞大,如果对地址做一一映射,映射表将会比物理内存还要大。这时就需要对内存进行分页映射,即将内存分为一定大小,如4KB大小的页,这些页面与物理内存中的4KB大小的页面一一对应,这就是内存分页机制。但是页表仍然很大,现代体系结构中一般使用多级页表来大幅减少页表所占用的空间,例如Linux中的四级页表:
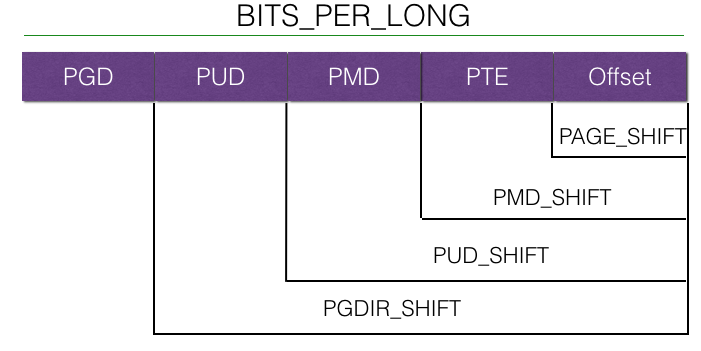
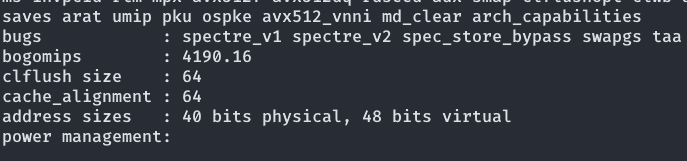
其中PGD、PUD等分别是一、二、三、四级页表项,Offset是页内部的地址。Linux在最新的Intel Xeon处理器上甚至使用了五级页表,具体处理器支持就不赘述了。值得注意的是,页表需要硬件支持,也就是CPU的内存管理单元(MMU)的支持。以下是一个Intel Xeon Gold 6230的MMU支持,可以看到40 bits physical,也就值它的MMU支持40位的硬件寻址,48 bits physical也就是目前Linux四级页表所支持的虚拟地址空间大小。
那页面置换又是什么?
页面置换也来自一个几乎所有的现代操作系统都拥有的功能——交换机制。当物理内存接近满的时候,操作系统为了使整个系统仍然可用,会将一部分不常使用的页面移到磁盘上,为更经常使用的页面腾出空间。当然,这样的做的代价是会降低性能,这个机制也不是万能的,当活跃使用的内存也借近物理内存大小的时候,系统依然会变得几乎不可用,不过至少这样的机制使得系统有机会自己恢复,而不是不得不由OOM Killer杀死一些进程。这个交换机制显然需要一个优秀的算法来判断哪一部分页面是“陈旧的”,这就引出了这篇文章的主题——页面置换算法。
页面置换算法
操作系统发展了50年,页面置换算法也在不断地改进,我们先来盘点一下曾经出现过的页面置换算法有哪一些。
最优算法:想得真美,甚至关于“最优”定义也取决于实际场景。- NRU(最近未使用)算法:一个简易的算法,维护一个链表,每次淘汰末端的页,每次读取时将页面移至表头。是可以接受的算法,实现简易,性能损耗小。
- FIFO:维护一个队列,每次直接清理队列头的页面。几乎无性能开销,但是效果不好。
- Second Chance FIFO:维护一个循环队列,每次清理访问标志位为0的页面,每次访问后将标志位置为1,这样只要周期内页面有访问,就会免遭清理,除非所有的页都为1。由于使用循环队列,内存操作较多,故一般使用下面一个算法。
- 时钟算法:指针和环形链表/队列实现SCFIFO,消除了内存操作,也是较为常用的算法,效果较好,比较NRU有较大改善。
- LRU(最近最少使用)算法:对于最优算法在大多数情况下很好的近似,效果优异,但是较难实现,目前的算法要不就是时间复杂度较高,要不就是空间复杂度较高。大多数时候还需要硬件支持。
- NFU算法:由软件模拟的LRU,使用的频度Freq由系统时钟中断处理程序统计,效果较好,但是有一定的性能开销,且没有实现“最近”。
- 老化算法:在NFU基础上加入频度老化,实现了“最近”,越久的使用次数权重越低。
Linux内核现在使用的页面置换算法是两级的软件LRU,也就是分为active和inactive类型的两个链表,并实现软件LRU(NFU)算法,由于基于硬件的LRU在当今的体系结构中无法实现,下文中我们把这一种算法简称为LRU。
两级LRU的问题
TL;DR
现行的算法CPU开销太大,而且经常做出错误的决策。
粒度
Active/Inactive这两种分类在现在的硬件环境下,实在是一个相当粗的粒度。要知道,Linux统治的服务器领域中,内存上T的并不少见,甚至是很常见。Intel近几年推广的傲腾内存更是对内存调度提出了更高的要求。这个活动/非活动的分类并不是一个好的分类方法,像文件存取这样的情境下,经常会有周期性的内存操作,而这时页面会在两个表中来回移动,并不能很好表现这个页面是否是活跃的。而许多正在执行的可执行文件的代码段常常被移除,仅仅是因为它们在相当短的一段时间内没有被使用。这导致了在安卓和ChromeOS上交互进程的反应延迟。
倒排页表扫描的性能问题
由于LRU算法需要周期性地根据倒排页表(rmap)以更新页面的访问计数器,但是,rmap拥有相当复杂的数据结构,局部性很差,导致在扫描rmap的时候CPU缓存命中率很不理想。现代CPU的缓存命中率对执行速度由极大的影响,缓存命中率低下可以使CPU的执行速度下降到峰值的10%甚至更低。
多级LRU
Yu Zhao最近提交的Patch中提出了Multigenerational LRU算法,旨在解决现在内核使用的两级LRU的问题。这个多级LRU借鉴了老化算法的思路,按照页面的生成(分配)时间将LRU表分为若干Generation。在LRU页面扫面的时候,使用增量的方式扫描,根据周期内访问过的页面对页表进行扫描,除非这段时间内访问的内存分布非常稀疏,通常页表相对于倒排页表有更好的局部性,进而可以提升CPU的缓存命中率。
在邮件列表中Yu Zhao说明了他使用更改后的算法在几个模拟场景中的情况:
- Android:减少了18%的low memory kill,进而减少了16%的冷启动。
- Borg(Google的云资源编排系统):活跃内存占用降低了。
- ChromeOS:非活跃页面减少了96%的内存占用,减少了59%的OOM Kill。
结语
Linux内核页面置换算法的修改影响非常巨大,哪怕只是“微小”的调整。因为Linux的使用场景并不仅限于常用的几种情况,因此这个Patch需要经过相当长的一段讨论和各个开发者的测试才可能最终被合并进入主线。虽然大部分的内核开发者还没有发表对此的意见,但已有部分人对这个新算法持有积极的态度和较好的评价,所以我也认为这个Patch将会最终进入Linux内核主线。
[2023-01-07] Update: MLRU 已在 Linux 6.2 合并进入主线内核
深入阅读
- The multi-generational LRU
- [PATCH v1 00/14] Multigenerational LRU
- Long-term SLOs for reclaimed cloud computing resources https://research.google/pubs/pub43017/
- Profiling a warehouse-scale computer https://research.google/pubs/pub44271/
- Evaluation of NUMA-Aware Scheduling in Warehouse-Scale Clusters https://research.google/pubs/pub48329/
- Software-defined far memory in warehouse-scale computers https://research.google/pubs/pub48551/
- Borg: the Next Generation https://research.google/pubs/pub49065/
