
预计阅读时间: 37 分钟
本文翻译自 ChipsAndCheese,原文为英文,原文链接:https://chipsandcheese.com/2024/03/13/loongson-3a6000-a-star-among-chinese-cpus/ 原作者:clamchowder
本文中文翻译首发自我的博客 https://blog.eastonman.com/blog/2024/03/loongson-3a6000-a-star-among-chinese-cpus/ ,翻译已取得 ChipsAndCheese 编辑/原作者授权。因英文原文无公开的授权协议,本译文也禁止转载,如需转载请先联系我或 ChipsAndCheese。
现在,我们将看看龙芯新一代的 3A6000 CPU。3A6000 同样是一个四核的 CPU,时钟频率在 2.5GHz,但使用了新的 LA664 核心。相较于 3A5000 的 LA464 核心,LA664 是一个巨大且雄心勃勃的改进。尽管龙芯保持了相同的总体架构,但 LA664 拥有更宽、更深的流水线和更多的执行单元。让事情看起来更好的是,LA664 支持了 SMT(同时多线程)。如果正确实现的话,SMT 可以在很小的面积开销下增加多线程的性能。然而,要把 SMT 做好并不容易。
3A6000的性能测试
7-Zip 是一个文件压缩程序,它有很高的压缩率,但对CPU的要求也很高。7-Zip 几乎完全使用标量整数指令,因此 SIMD 扩展并不提供什么加速。这里,我们通过压缩一个大型的 ETL 性能追踪文件来对比性能。
3A6000 相比它的前身 3A5000 有 38% 的巨大性能提升。如果考虑 SMT 的话,这个提升还更大。在这个 workload 中每个核心只使用一个线程时,四核 LA664 与四核 Zen1 差不多。因此,LA664 的 IPC 性能非常好,因为它只运行在 2.5GHz 的频率上,但低频阻止了它超越 AMD 更新的产品。
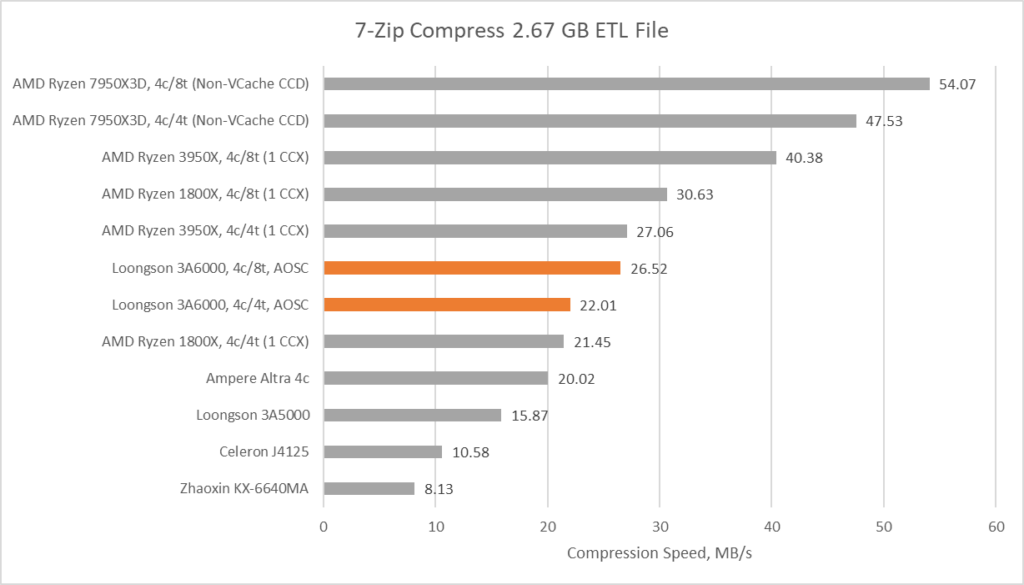
当使用所有线程时,SMT 为 3A6000 提供了 20% 的性能提升。与此同时 AMD 的 SMT 在 Zen1 和 Zen2 上有 40% 以上的收益。SMT 的作用是提供了更多的显式并行性,帮助 CPU 隐藏延迟并更好地填满流水线。一方面,高 SMT 收益表明核心的 SMT 实现是经过精心调整的。另一方面,这又意味着核心在运行单线程时没有很好地隐藏延迟。
与 7-Zip 不同,libx264 视频编码大量使用 SIMD 指令。在 x86 CPU 上,编码器将使用 SSE、AVX、AVX2 这些扩展来加速,甚至是使用 AVX-512。在龙芯的 CPU 上,libx264 会使用 LSX 和 LASX 这两种 SIMD 扩展。在这里,我转码一个4K的《守望先锋》游戏剪辑来对比性能。
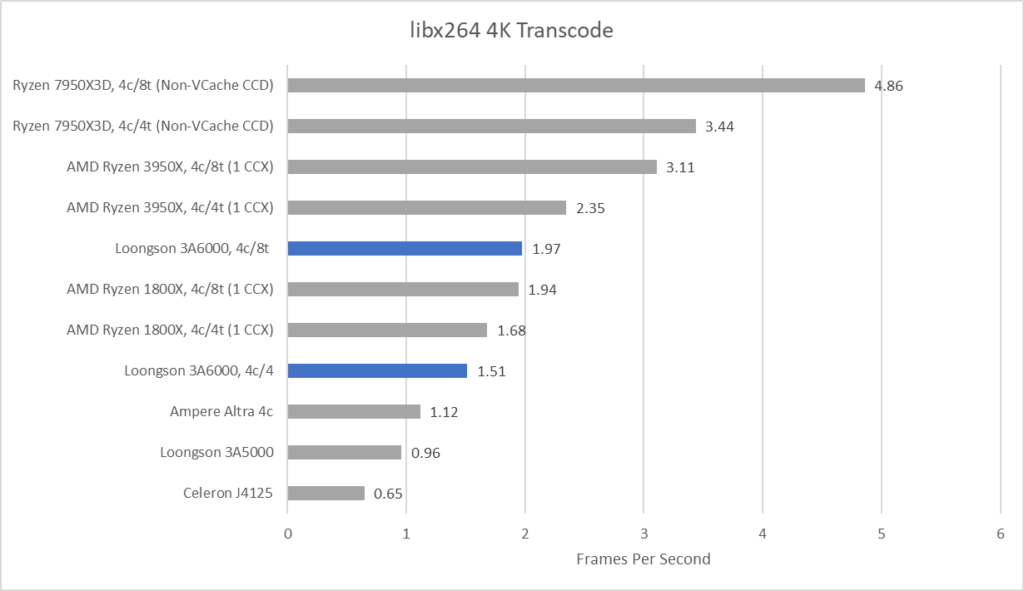
3A6000 和 Zen1 性能大概差不多,在使用所有线程和每个核心只运行一个线程的情况下互有胜负。Zen1 较高的 SMT 收益可能受到其弱的 AVX2 实现的限制。Zen2 和 3A6000 都有 30% 以上的 SMT 收益。因为架构经过了全面改进和有坚实的 AVX-512 实现,AMD 最新的 Zen4 架构在这些测试中遥遥领先。和之前一样,对于一个 2.5GHz 的 CPU 来说,3A6000 的表现还是非常令人钦佩的。
LA664 核心将龙芯从低性能的区域带入了能够与 AMD 和 Intel 的旧型号竞争的行列。Zen1 也和 Haswell 性能差不多,而这两种架构即使在今天也是仍能一战的。接下来让我们来看看是什么样的架构能让龙芯与那些高时钟频率的设计竞争。
核心架构
LA664 是一个 6 发射的乱序核心,拥有丰富的核内资源和较大的乱序窗口。它在这些方面已经可以与较新的 Intel 和 AMD 核心相媲美。
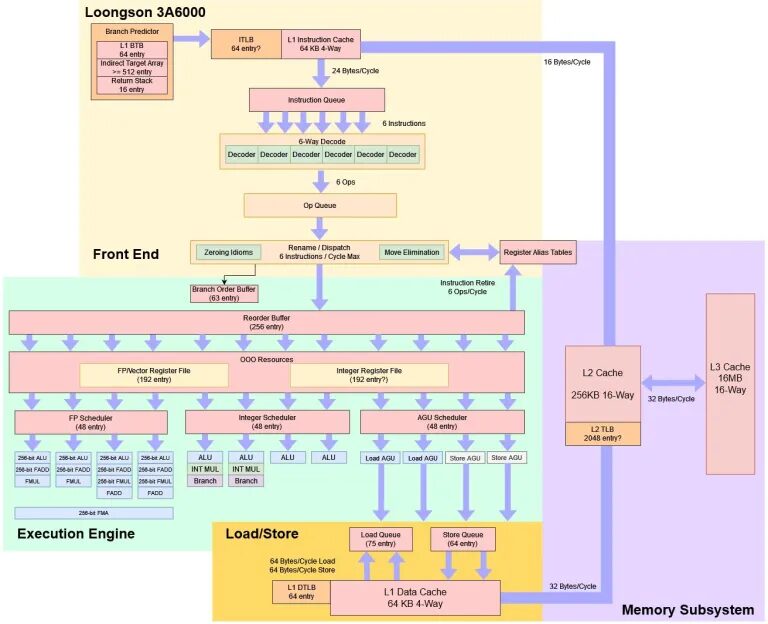
LA664 在 LA464 的基础上进行了改进。龙芯 3A5000 中的 LA464 核心是一个四发射设计,但在所有方面都相对保守。LA464 总体上是一个经得起考验的核心,没有明显的弱点,并为龙芯在 LA664 的改进提供了坚实的基础。毫不意外地,LA664 继承了 LA464 的总体架构。
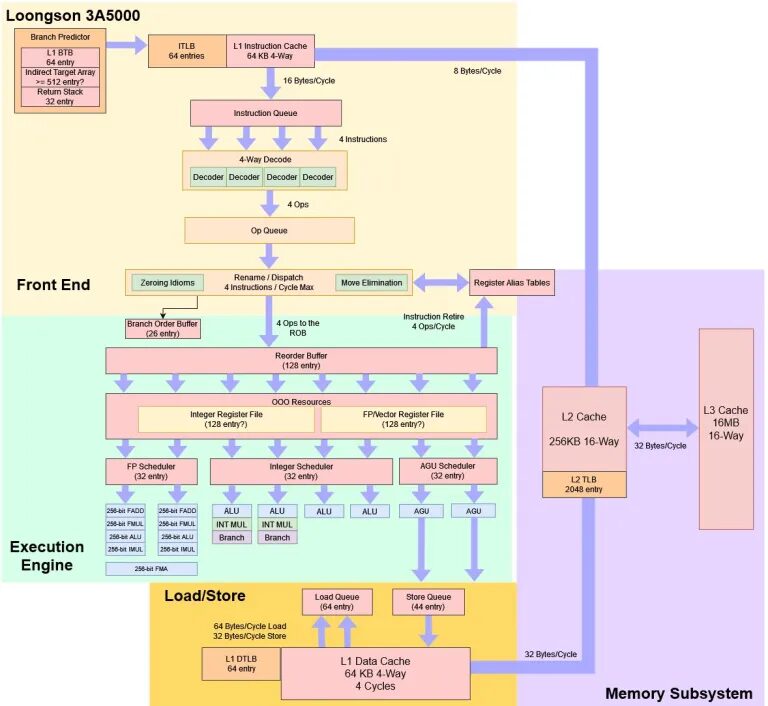
当然,架构图不能覆盖全部的细节。类似分支预测、执行单元延迟和访存性能等因素可能会对性能产生巨大的影响。
龙芯3A6000的前端
分支预测
CPU 分支预测器的责任是指导前端取指,告诉 CPU 分支将会走向哪个方向。这非常重要,因为如果分支预测器预测错误,CPU 的后端将会在错误路径上浪费大量的性能、功耗和时间。
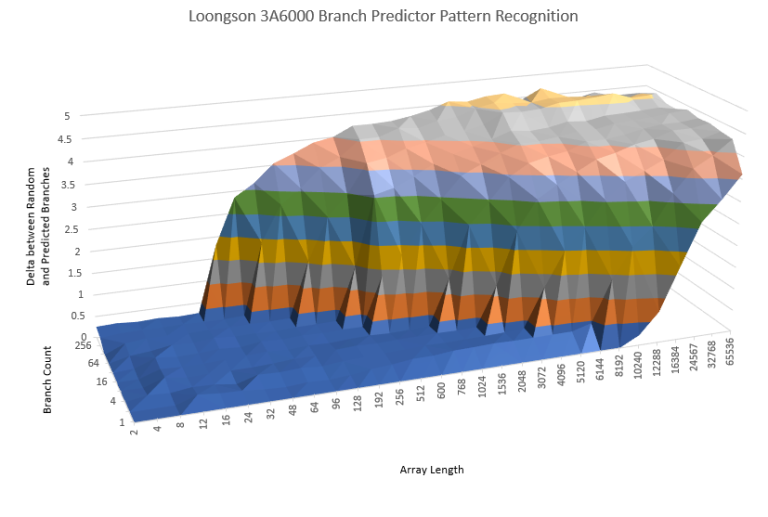
3A6000 的分支预测器拥有令人印象深刻的模式识别能力,在我们迄今为止看到的中国 CPU 中显然是最优秀的。它与我们在 3A5000 中所见到的大相径庭,并且几乎能够与最新的 Intel 和 AMD 的 CPU 相媲美。但是 AMD 一直在分支预测器能力上投入了大量精力,这使他们的 Zen3 架构仍然领先一些。
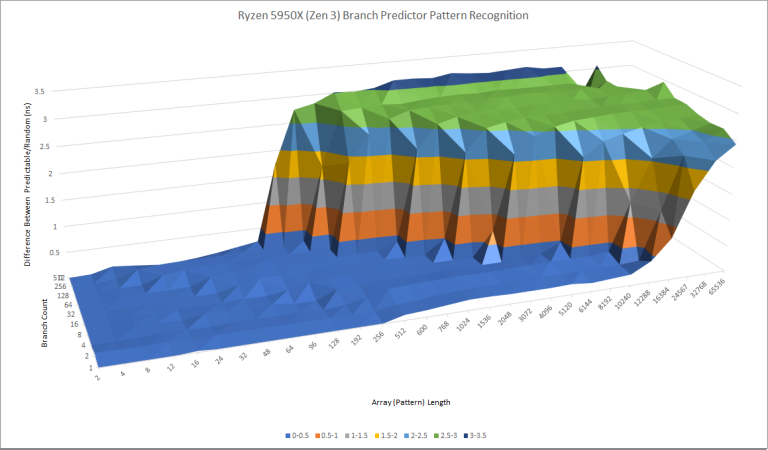
Zen3 通过使用覆盖重定向的预测器来实现这一点:大多数分支行为简单,可被一级预测器迅速处理;仅对具有长期历史依赖的分支,能力更强但速度较慢的二级预测器才需要介入。这种方案使 Zen3 的分支预测器能在不牺牲预测速度的前提下跟踪非常长的分支历史。
即使 3A6000 无法与 AMD 最新的核心匹敌,龙芯在这一领域取得的进步仍值得赞扬。3A5000 的预测器看起来更适合 2000 年代中期到 2010 年代初的高性能核心,而不是近十年的产品。龙芯在分支预测器的改进无疑是 3A6000 改善性能的一大因素。
分支预测器速度
分支预测器要快速且准确,以避免出现供指问题。分支目标缓冲(BTB)缓存分支的目标,让预测器在实际分支指令被从 ICache 中取出并译码之前就能提供一个推测的指令流。LA664 拥有 64 项的 L1 BTB,能够连续(或者说Zero-Bubble地)处理 taken 的分支。BTB 缺失的情况很可能简单地等待 64KB 的 L1i 中的指令被取出和译码,然后才计算分支目标。这在实际效果上相当于 L1i 充当一个 1K-4K 项的 L2 BTB。
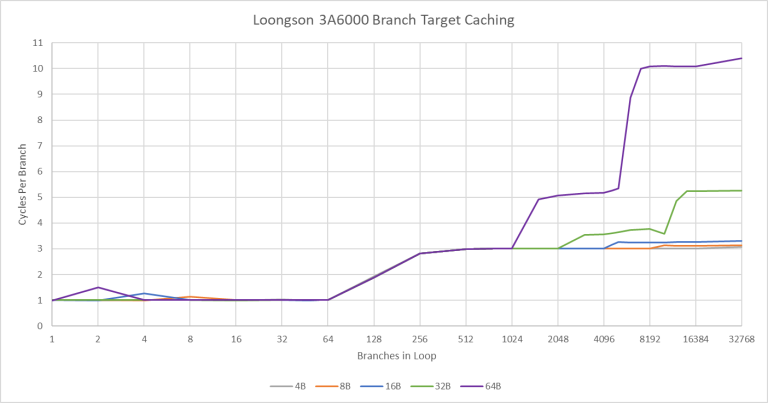
相比之下,AMD 和 Intel 最近的架构都使用解耦的大型 L2 甚至 L3 BTB。只要分支 footprint 能被 BTB 覆盖,从下级 BTB 获取地址可以比从 ICache 获取更快,AMD 的 Zen4 就利用这一点来做到非常低延迟的分支处理。
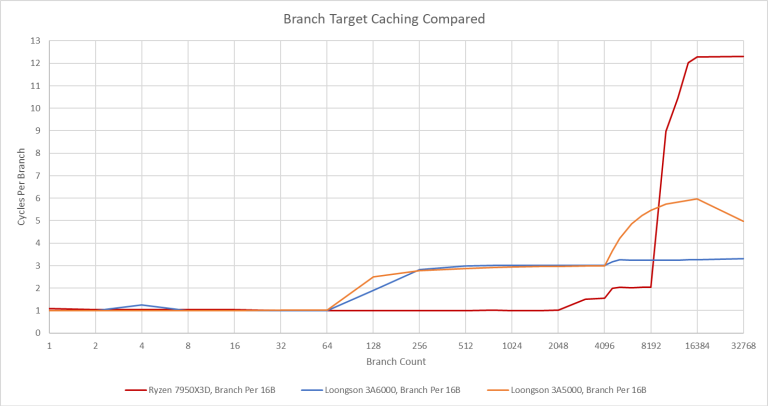
此外,从指令缓存解耦 BTB 有助于维护高 IPC,因为预测器得以免受 L1i 缺失延迟的影响。但龙芯决定放弃一个大的、解耦的 BTB 并非独一无二。Tachyum Prodigy 也做出了同样的决定,因为他们发现用标准库达到他们的目标频率将会太贵。如同 Tachyum 的 Prodigy,3A6000 通过使用一个大的 64KB 指令缓存来补偿这一点。如果 L1i 缺失变少,那这种做法弱点就不那么明显了。
3A6000 似乎还有更加积极的 nextline 指令预取。上面的测试中,分支仅仅跳到到下一个 16B 对齐的块,因此 nextline 指令预取器可以很好地工作。相比之下,AMD 的预取完全由分支预测器驱动。一旦超过了 BTB 容量,就无法隐藏 L2 延迟。
间接分支预测
与直接分支相比,间接分支更难预测。间接分支并不是直接编码跳转目标,而是跳转到寄存器中的地址。3A6000 在间接分支预测方面做得非常好。
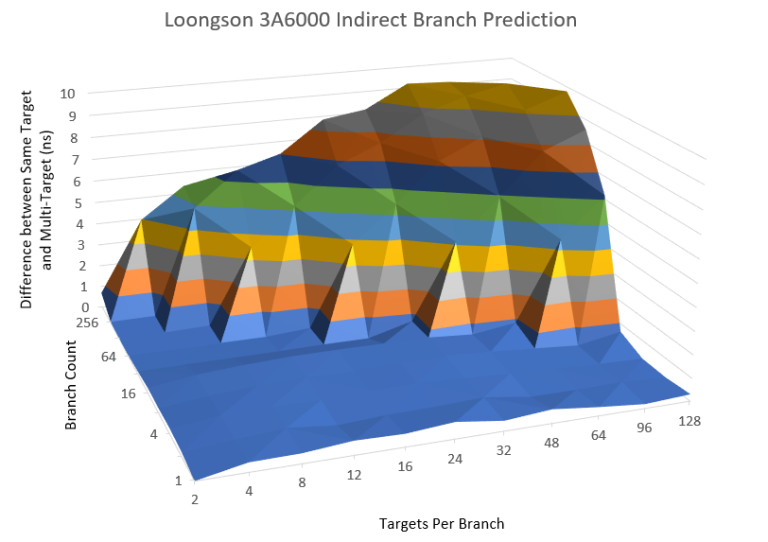
3A6000 可以跟踪总共 1024 个间接跳转目标,是 3A5000 的两倍。3A5000 只能跟踪大约 24 个间接分支,而 3A6000 可以轻易跟踪超过 128 个间接分支。相比之下,Zen2 也可以跟踪 1024 个间接跳转目标,因此 3A6000 在这一点上与较新的 x86 CPU 非常接近。
返回地址预测
返回指令作为一种特殊类型的间接分支,经常是以 call-return pair 的形式出现。许多处理器倾向于使用一个专用的返回地址栈。当分支预测器遇到一个调用指令时,它会将一个地址压入这个栈中。当它遇到一个返回指令时,它会从栈中弹出一个地址。有趣的是,3A6000 将返回地址栈的容量从 3A5000 的 32 项减少到了仅仅 16 项。如果核心的两个 SMT 线程都在运行,有效容量甚至可能进一步降低到 8 项。
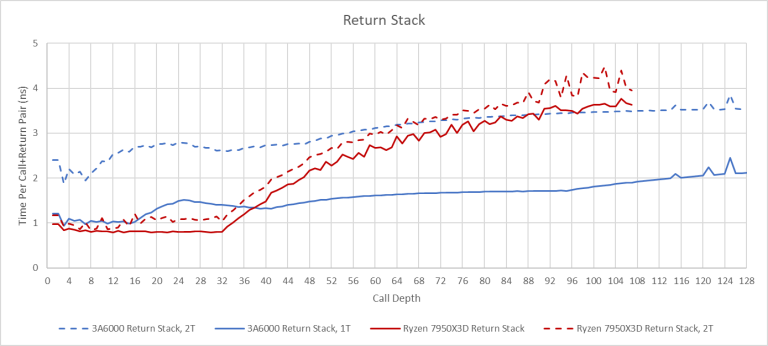
将返回栈容量降低到 16 项在某种程度上是有道理的,因为即使是一个较小的返回栈也能覆盖到大多数调用/返回情况。龙芯可能是在返回地址栈溢出示回落到间接分支预测器,因为溢出时 3A6000 只会遭受轻微的性能损失。Intel 采用同样的这种策略。在这种情况下,返回栈地址可以被视为一个功耗和性能优化的措施,而不是性能关键路径上的一部分。
分支预测准确率
7-Zip 和其他压缩程序通常对 CPU 的分支预测器构成巨大的挑战。3A6000 的分支预测器表现出色,与 Zen1 在 MPKI 上持平。
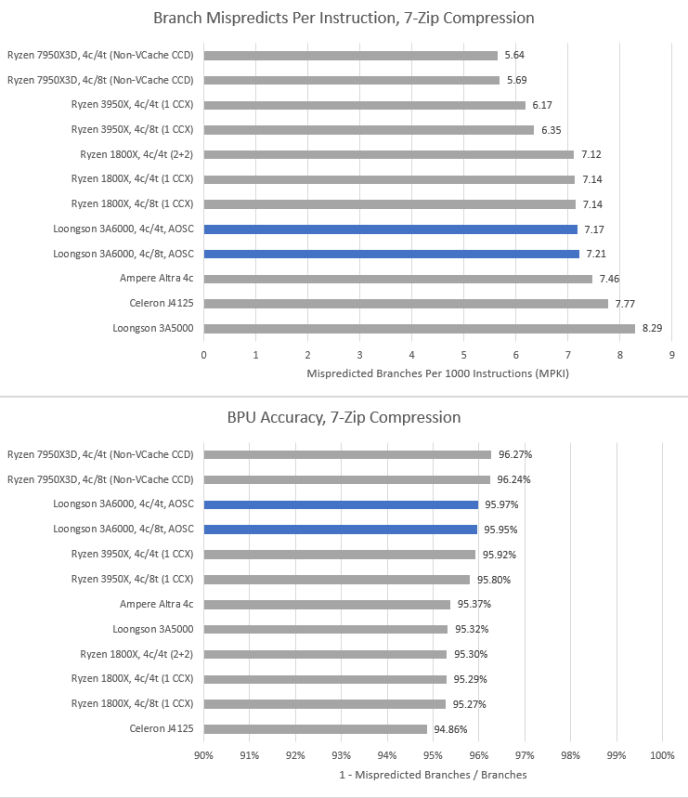
在准确率方面,3A6000 与 Zen2 不相上下。在跨 ISA 对比时,准确率是一个更好的衡量标准,因为 3A6000 能够以更少的执行指令完成工作负载。MPKI 较高可能是因为龙芯的指令流中分支的比例更大。AMD 最新的 Zen4 架构仍然领先,但龙芯在分支预测器方面取得了值得赞扬的进步,它远远优于3A5000。
libx264 拥有较少并且更好预测的分支,但我们仍然可以看到测试 CPU 之间的差异。在这个测试中,ISA 差异对龙芯不利。3A6000 的 MPKI 较低,但这仅是因为它完成工作负载执行了更多的指令。当有更多的非分支指令要处理时,误预测的影响就变得不那么重要了。
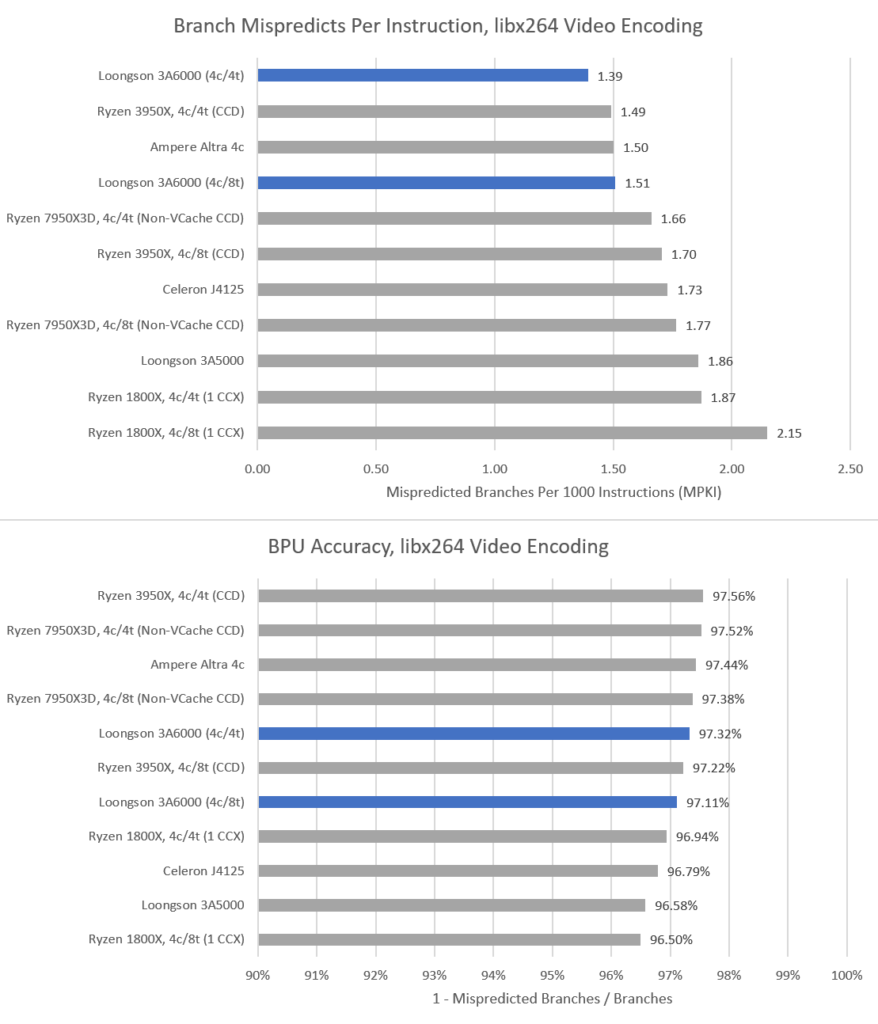
3A6000 的分支预测器表现可以与 AMD 的 Zen2 相媲美。龙芯再次显示出他们在设计分支预测器能力上的竞争力。
指令获取
一旦分支预测器决定了指令流,就轮到指令缓存来为核心提供指令。与它的前辈一样,3A6000 拥有一个大型的 64KB 4 路 L1i。Intel 和 AMD 的 CPU 只有 32KB 的 L1i,相比来说 3A6000 有一个相当大的L1i。64KB 的 L1i 向一个 6 宽的译码器供指,这使 3A6000 有比它的前任宽 50% 的前端。
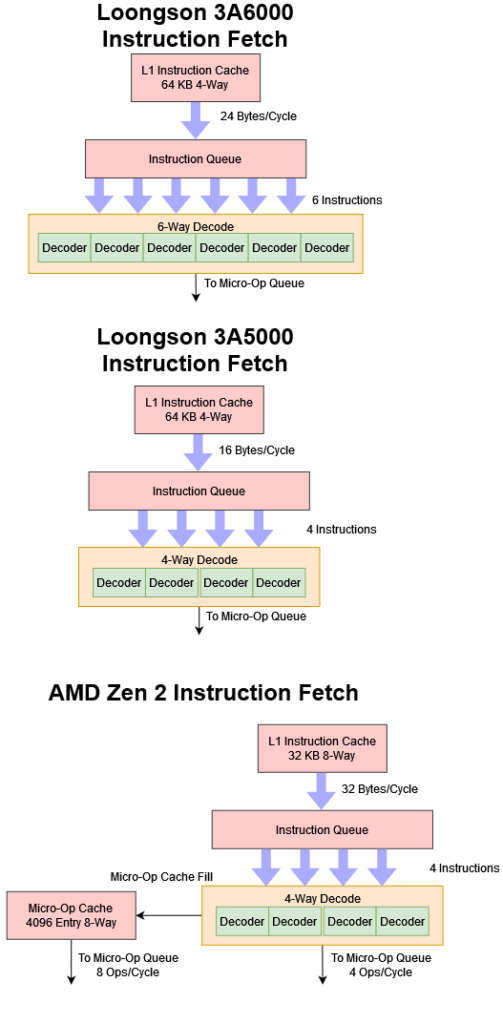
AMD 和Intel 的高性能 CPU 使用 uOp Cache,这可以让它们在提供更高吞吐量的同时避免指令译码开销。自 Zen 架构以来,AMD 的 uOp Cache 理论上可以在每周期提供一整行的 8 个 uOp,但是下游的重命名宽度限制了核心的吞吐量。
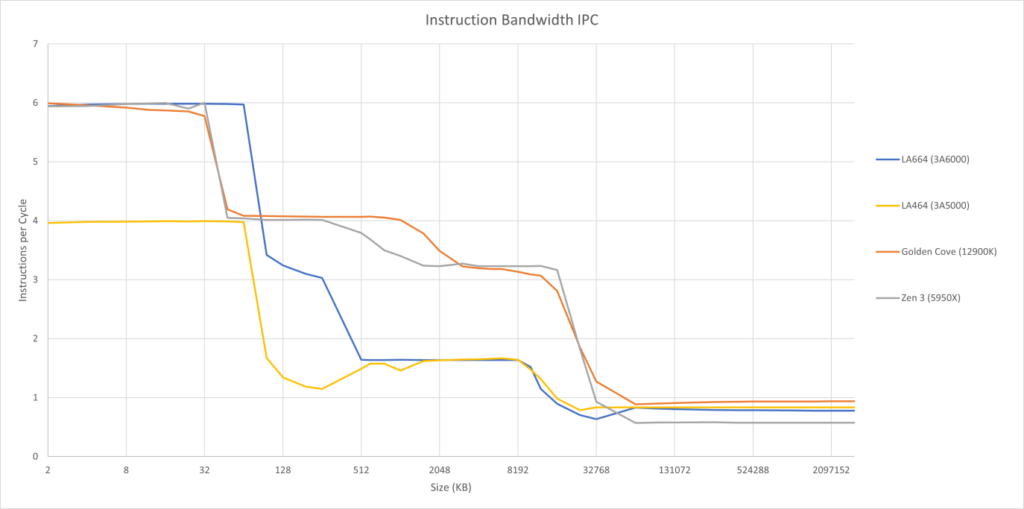
当代码溢出 L1i 时,龙芯 3A6000 保持了良好的吞吐量。3A5000 在运行 L2 中的代码时出现了不明原因的指令带宽不足。龙芯在 3A6000 中解决了这个问题,它可以在代码被 L2 覆盖时维持每周期 3 条指令的吞吐。
不幸的是,在指令 footprint 增大到 L3 以后,情况并没有那么乐观。看起来龙芯在 3A6000 上并没有改进他们从 L3 获取指令的能力。这是有些遗憾,因为 Golden Cove 和 Zen3 都可以每周期获取超过三个 4 字节指令,而龙芯的 CPU 连每周期两个都不行。
重命名和分配
指令被解码成 uOp 后,CPU 需要分配后端资源。这些资源追踪指令状态,允许 CPU 尽快执行指令,同时确保正确的程序行为和异常处理。这个阶段还通过寄存器重命名机制打破假依赖,并在执行引擎中实现了其他技巧,以暴露更多的指令级并行性。
LA664 的重命名阶段有 move elimination,对寄存器置零有特殊处理,类似于 x86 CPU 识别原地 XOR 的行为。重命名完全消除了这样的操作,意味着它们不会消耗更下游的执行资源。
| 测试项目 | 3A6000 IPC | Zen 4 IPC |
| 有依赖的move | 2.00 | 5.71 |
| 无依赖的move | 3.64 | 5.73 |
| 寄存器置零 | 5.35 (li.d) | 5.73 (XOR) |
龙芯针对寄存器 move 进行了一些优化。有依赖的 move r,r 指令可以每周期执行两条,所以 LA664 有时可以在重命名表中通过指针操作以打破这种依赖。然而,它不能以全速执行move,寄存器 move 仍然需要通过 ALU。
Intel 和 AMD 都有更激进的消除,能够全速消除寄存器 move,无论是否存在依赖。Intel 的 Golden Cove 还可以在重命名阶段消除带小立即数的加法,进一步减轻执行阶段流水的负担。
乱序执行
为了实现乱序执行,重命名和分配阶段需要在必要的队列和缓冲区中找到空位才可以继续。更大的结构允许核心有更大的乱序执行窗口,使其更能隐藏延迟并利用指令级并行性。龙芯 3A6000 拥有非常大型的乱序引擎,这是在 3A5000 基础上的巨大进步。
| 结构 | 何时需要占用 | LA664 (龙芯 3A6000) | LA464(龙芯 3A5000) | Zen3 | Golden Cove |
| Reorder Buffer | – | 256 项 | 128 项 | 256 项 | 512 项 |
| 整数寄存器堆 | 目的寄存器为整数寄存器 | 192 项 | 128 项 | 192 项 | 280 项 |
| 向量/浮点寄存器堆 | 目的寄存器为向量/浮点寄存器 | 256bit 192 项 ,6KB 总容量 | 256bit 128 项 ,4KB 总容量 | 256bit 160 项 ,5KB 总容量 | 512bit 228 项 + 256bit 104 项,16.875KB 总容量 |
| 调度队列 | 等待执行 | 48 项整数, 48 项浮点, 48 项访存 | 32 项整数, 32 项浮点, 32 项访存 | 4×24 项整数 ( 其中3个与AGU共享) 2×32 项浮点+ 64 项顺序队列 | 97 项运算,70 项Load,38 项Store |
| Load Queue | 读内存 | 80 项 | 64 项 | 116 项* | 192 项 |
| Store Queue | 写内存 | 64 项 | 44 项 | 64 项 | 114 项 |
| 分支缓冲 | 控制流指令 | 64 项 | 26 项 | 48 项 Taken, 117 项 Not Taken | 128 项 |
与 3A5000 相比,诸如寄存器堆和 LSQ 等主要结构至少增加了 25% 的大小。LA464 的分支缓冲看起来太小了,而 LA664 解决了这个问题。LA664 最终拥有与 AMD 的 Zen3 相当的乱序能力。但 Zen3 和 LA664 与 Intel 的 Golden Cove 相比起来仍然小,Golden Cove 有着巨大的 512 项 ROB 和其他更大的结构。

SMT实现
更大的乱序缓冲区对于提高单线程性能至关重要,但会遇到收益边际效应。SMT 通过向操作系统暴露多个逻辑线程,并在这些线程之间分配资源来对抗这种收益递减。因此,一个启用了 SMT 的 CPU 可以保持单线程的高性能,与此同时如果有多个线程活跃,它就像几个较小的核心一样工作。AMD、Intel 和龙芯都决定为每个核心设计两个 SMT 线程。
虽然 SMT 的好处很明显,但实现难度很大。CPU 必须能够动态地在多个线程之间切换。工程师必须决定在两个线程的模式下如何管理各种核心结构。具体来说这种情况下,一个结构的处理方式可以是:
- 复制。每个线程获得一份完整的资源。在单线程模式下,第二份资源不使用。这不是一个面积高效的方式,但可能更容易 tuning 和验证。不需要担心线程饥饿,如果第二个线程变得活跃,也不需要清空部分资源。
- 静态分区。每个线程获得一半的资源。当一个线程处于停止状态时,另一个线程可以使用所有资源,所以这种方法是面积上更高效的。它更难验证,因为当两个线程都工作时,资源需要清空一半并重新配置。但由于将结构切分为两半确保了线程之间某种程度的公平性,所以 tuning 仍然不是太难。
- 使用 water-mark。在 2T 模式下,一个线程可以占用资源直至 high water-mark。这种做法更灵活、有更多潜在的性能,但 tuning 更难。较高的 water-mark 可能会提高一个线程的性能,但对另一个(饥饿的)线程有严重的影响。
- 竞争性共享。这就是自由竞争:即使另一个线程活跃,一个线程也可以使用所有的资源。这种情况灵活性和潜在的性能都可以达到最大。例如,如果一个线程运行浮点代码,另一个运行纯整数代码,竞争性共享调度器将允许两个线程用满他们最需要的资源。但 tuning 和验证变得更难。线程饿死可能会更加常见,工程师必须小心避免这种情况。
龙芯选择了一个保守的 SMT 实现,其中大多数资源都是静态分区的,包括 ROB、寄存器堆和 LSQ。
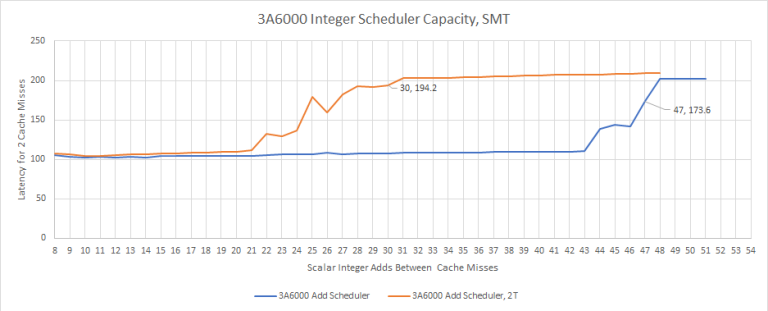
3A6000 的调度器是用 water-mark 的。运算单元调度器的高水位标记似乎在 30 项左右,所以在 3A6000 上运行的线程即使在其 SMT 兄弟线程活跃时也几乎可以使用与在 3A5000 上一样多的调度器大小。
| 结构 | 3A6000 | Zen 2 |
| Reorder Buffer | 静态分区 每线程约 122 项 | 静态分区 |
| 整数寄存器堆 | 静态分区 每线程约 69 项 | 竞争共享(可通过 QoS 等调整) |
| 向量/浮点寄存器堆 | 静态分区 每线程约 64 项 | 竞争共享(可通过 QoS 等调整) |
| Load Queue | 静态分区 每线程约 38 项 | 竞争共享 |
| Store Queue | 静态分区 每线程约 30 项 | 静态分区 |
| 整数调度队列 | Watermarked 每线程最大 30 项 | 竞争共享 |
| 访存调度队列 | Watermarked 每线程最大 36 项 | 竞争共享 |
| 浮点调度队列 | Watermarked 每线程最大 30 项 | Watermarked 每线程最多 64 项 SQ + NSQ (总共 100 项) |
AMD Zen2 的重排序缓冲使用静态分区,并对浮点调度队列和非调度队列采用某种水位标记方案。但在其他方面,AMD 采取了非常激进的 SMT 策略。寄存器堆、LSQ 和整数调度队列是竞争性共享的。这可以部分解释Zen2 令人印象深刻的 SMT 收益。
对于龙芯来说,采取一个不那么激进和更容易验证的方法是合理的。3A6000 是他们首个支持 SMT 的 CPU,过于雄心勃勃总是容易导致失败。
整数执行
3A6000 的整数执行单元看起来相比前代变化最少,但调度器容量增加 50% 应该会有更好的 ALU 端口利用率。与 3A5000 一样,3A6000 有四个端口的 ALU 能够执行常见操作。两个端口可以处理分支,两个用于整数乘法。这个配置与 Zen2 大致相似,但龙芯有两个整数乘法单元,而 Zen2 只有一个。Zen2 有更大的总调度容量,但 Zen2 是分布式调度器,与龙芯的统一调度器并不能直接比较。Zen2 上可能会出现其中一个 16 项的队列提前填满,这在重命名阶段将会由于资源不足发生阻塞。
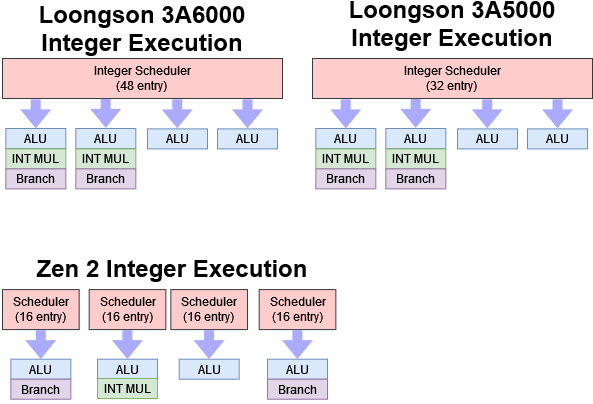
龙芯在整数除法的吞吐量和延迟上进行了改进,从 3A5000 的每周期 0.11 个指令和 9 个周期的延迟提高到每周期 0.25 个指令和 4 个周期的延迟。除法器的改进是一个奇怪的选择,因为大多数代码会避免使用 DIV 指令,因为它在历史上就非常慢。也许是因为龙芯需要从头开始构建他们的软件生态系统,加速除法操作可能是一个值得的投资。
向量和浮点执行
龙芯的 3A5000 拥有 256 位的向量能力和 LASX 扩展,但实现较为保守,只有两个 256 位执行单元。3A6000 彻底改进了FPU,它现在有四个执行单元。所有四个管道都可以处理 256 位向量加法,这给 3A6000 提供了非常强大的浮点性能。竞品的 x86 CPU 只能每个周期执行两个 256 位向量加法。256 位向量乘法和基础向量整数操作性能与 Zen2 相似。
奇怪的是,标量浮点操作没有得到同样的增强。只有两个单元可以处理标量浮点加法。更奇怪的是,标量浮点乘法似乎和向量乘法使用不同的流水线。
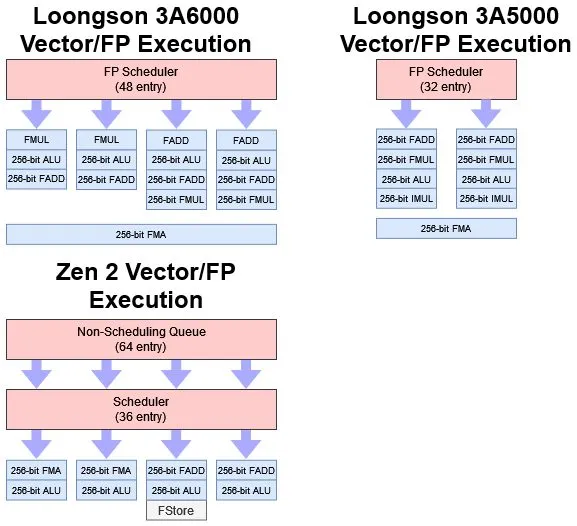
即使龙芯增加了额外的浮点单元,融合乘加(FMA)的峰值吞吐量还是保持不变。LA464 和 LA664 都可以每个周期执行一个 FMA 操作,它们的 FMA 吞吐量是 AMD 的 Zen2 或 Intel 的 Skylake 的一半。
| 指令 | LA664 | LA464 | Zen3 | Golden Cove |
| 256bit FP64 向量加法吞吐量 | 4 per cycle | 2 per cycle | 2 per cycle | 2 per cycle |
| 256bit FP64 向量加法延迟 | 3 cycle latency | 5 cycle latency | 3 cycle latency | 3 cycle latency |
| 256bit FP64 向量乘法吞吐量 | 2 per cycle | 2 per cycle | 2 per cycle | 2 per cycle |
| 256bit FP64 向量乘法延迟 | 5 cycle latency | 5 cycle latency | 3 cycle latency | 4 cycle latency |
| 256bit FP64 向量 FMA 吞吐量 | 1 per cycle | 1 per cycle | 2 per cycle | 2 per cycle |
| 256bit FP64 向量 FMA 延迟 | 5 cycle latency | 5 cycle latency | 4 cycle latency | 4 cycle latency |
除了吞吐量外,龙芯改善了执行延迟。浮点加法的延迟为 3 个周期,与 Zen3 相等。然而,AMD 的 Zen3 和 Intel 的 Golden Cove 仍然有更低的浮点执行延迟。特别是 Intel,它可以在 2 个周期延迟内完成浮点加法,而且还是以更高的时钟频率运行。
和整数调度队列一样,浮点调度队列容量增加了 50% 至 48 项。单独就这一点来说可能就已经提供了比增加执行单元更多的浮点性能提升,两者结合使 3A6000 在向量和浮点工作负载中表现强大。
AMD 的 Zen2 也有一个四流水线 FPU,并且也在所有四个单元处理基础向量整数操作。然而,它使用一个聪明的非调度队列,即使它的 36 项调度队列填满,也能让后端保持更多的inflight浮点或向量操作,尽管它不能利用这些指令来找到额外的指令级并行性。
地址生成
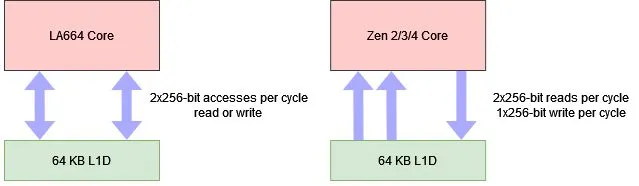
龙芯在 LA664 中相比于 LA464 显著强化了地址生成功能。LA464 拥有两个通用的 Load/Store 单元。LA664 将这分为两个 Load 和两个 Store 单元。
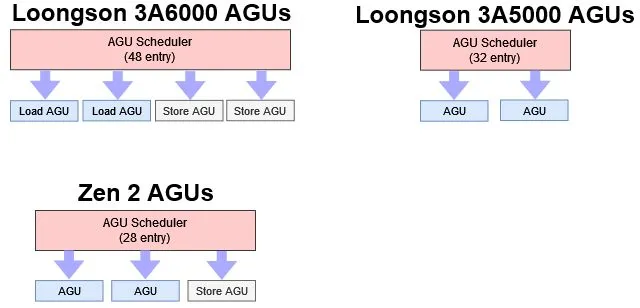
这意味着,LA664 每周期可以处理比 Zen2 更多的标量内存操作,与 Golden Cove 处理的内存操作量相同。Zen3 和 Golden Cove 在灵活性方面稍微领先于 LA664,可以每周期发出 3 个 Load。但 LA664 的 2 Load 每周期已经是从 LA464 的 1 Load 每周期的大幅升级。在 Store 方面,LA664、Zen3 和 Golden Cove 都是每周期 2 次标量 Store,而 LA464 只能每周期处理一个 Store。
| LA664 | LA464 | Zen3 | Golden Cove | |
| 每周期标量 Load | 2 | 1 | 3 | 3 |
| 每周期标量 Store | 2 | 1 | 2 | 2 |
| AGU 数量(标量内存操作发射宽度) | 4 | 2 | 3 | 4 |
LA664 可以每周期处理两个 256 位向量访存,这些访存可以是任意 Load/Store 组合。
内存序
一旦地址计算完毕,Load/Store 单元必须确保内存访问符合 ISA 的内存模型。Load 可能需要从之前的 Store 中获取结果。与之前的 3A5000 一样,3A6000 可以在大约 7 个周期的延迟中处理 Load 被包含于之前的 Store 的情况。只有部分是重叠的情况会产生 14 个周期的惩罚,可能是因为 Load 被阻塞直到 Store 退休并写回到 L1d。
Zen2 具有相同的 7 周期转发延迟和 14 周期的部分重叠惩罚。但 Zen2 可以以一个额外周期的惩罚处理 64B 缓存行间转发,而龙芯在这种情况下表现不佳。由于 Zen2 的时钟频率更高,所以龙芯 7 周期的转发延迟感觉有些长。Goldmont Plus 的目标频率也是 2.xGHz 接近 3GHz 的范围,它就是 5 周期的 Store-Load 转发延迟以及转发不能处理时的 10 周期延迟。

LA664 的 Store-Load 转发行为看起来与其前代相似。但 LA664 消除了非对齐 Store 的 10 周期惩罚,将其降低到仅 3 周期。这比 Zen2 稍好,Zen2 对于非对齐的 Store 需要 2 到 5 个周期的处理时间。

跨越 64B 边界的 Store-Load 转发仍然处理不佳,但惩罚从 31 周期降低到了可以接受的 21 周期。
缓存和内存访问
良好的缓存和内存层次结构对于任何现代高性能 CPU 的数据供给至关重要。3A6000 保留了类似的缓存层次结构,但在各个点上有细微的改进。

由于龙芯未能提高时钟速度,他们通过减少缓存访问路径中的流水线长度来降低延迟。
延迟
L1d 延迟从四个周期降低到三个周期。我认为低频 CPU 的设计目标应该是 3 周期 L1d 延迟,很高兴看到3A6000 实现了这一点。
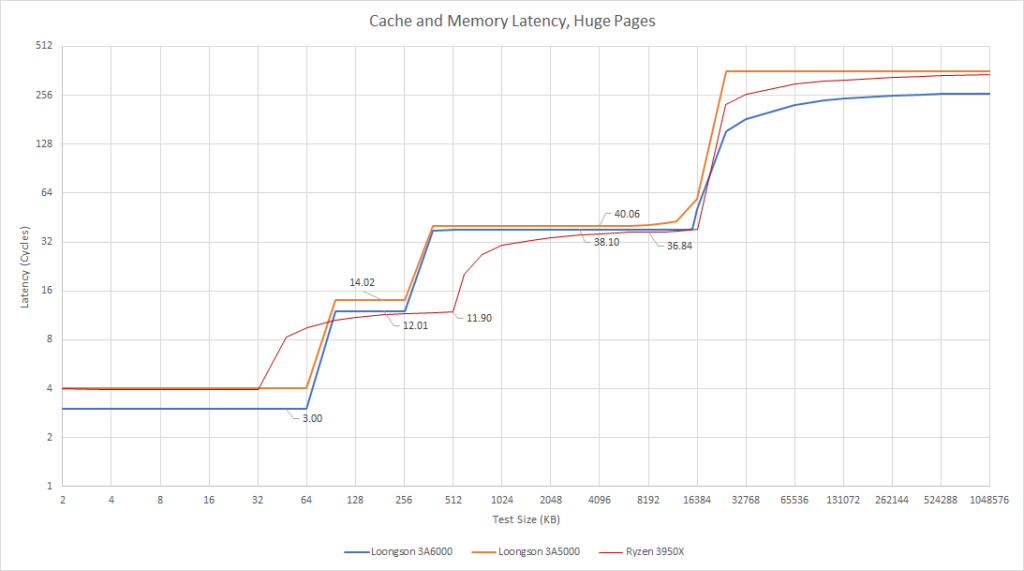
许多现代 CPU 使用 L2 作为中级缓存,使 L1 缺失不需要到相对高延迟的 L3 中查询。3A6000 继续使用256KB L2 缓存,类似于较早的 Intel 架构。最近的 AMD 和 Intel CPU 趋向于使用更大的 L2 缓存。Zen4 已经转向使用 1MB L2 缓存,而 Intel 的 Raptor Lake 选择了巨大的 2MB L2。尽管龙芯未能实现更大的 L2,但他们将延迟从 14 个周期降低到 12 个周期。假设 L1 以同样的速度处理命中和缺失的话,L1 到 L2 的路径上可能只减了一拍。
| 内存层级 | 3A6000 | 3A5000 | Zen 2 (3950X) |
| L1d | 64 KB 3 周期延迟 | 64 KB 4 周期延迟 | 32 KB 4 周期延迟 |
| L2 | 256 KB 12 周期延迟 | 256 KB 14 周期延迟 | 512 KB 12 周期延迟 |
| L3 | 16 MB 38 周期延迟 | 16 MB 40 周期延迟 | 16 MB 37 周期延迟 |
| DRAM | 104.19 ns ~263 周期延迟 | 144.52 ns ~361 周期延迟 | 77.25 ns ~341 周期延迟 |
Zen2、3A6000 和 3A5000 都有一个四核共享的大型 16MB L3 缓存。3A6000 减少了几个周期的 L3 延迟,尽管这可能是因为查询 L2 加快了两个周期。
最后,DRAM 延迟从 144ns 改进到了 104ns。3A5000 的 DDR4 控制器很糟糕。它只是恰好被较低的时钟频率“拯救”了,使得它对 IPC 的影响没那么大。3A6000 获得了大大改善后的内存控制器。104ns 还是不够好,但以周期数计的话,它的延迟降低到了比高时钟频率的 3950X 要低。因此 3A6000 至少通过减少 DRAM 访问延迟的周期数来缓解了它的低时钟频率劣势。然而,104ns 对于一个单片 DDR4-2666 的配置来说并不是很好。
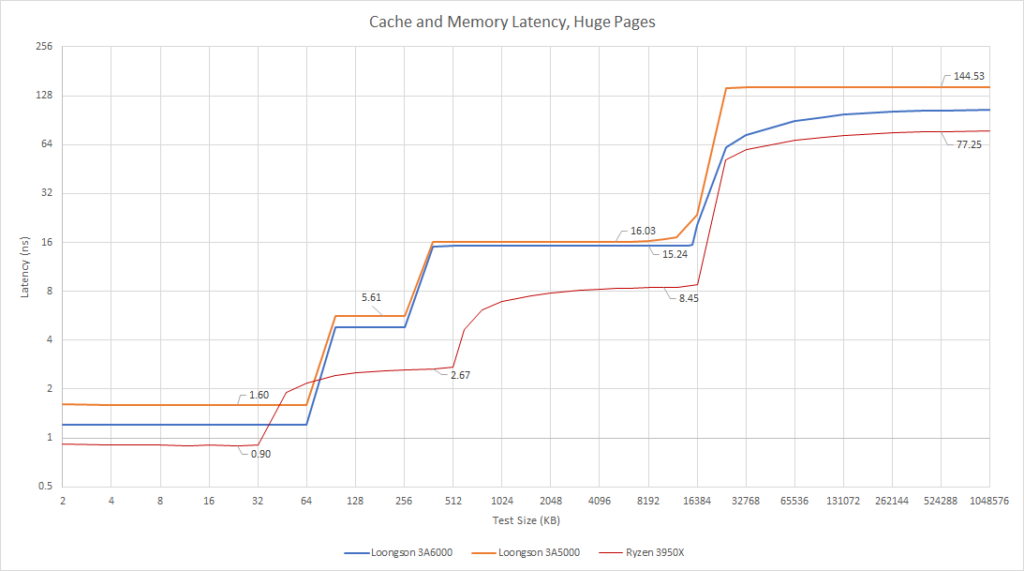
尽管 3A6000 在延迟的周期数上具有竞争力,我们必须考虑实际的延迟,因为龙芯无法将其 CPU 的时钟频率提升到现代 AMD 和 Intel CPU 运行的水平。这并不是对 LA664 有利的情况。在包括 L1 在内的每一缓存它都较慢。这解释了为什么 LA664 在拥有更多乱序能力和更高 IPC 的情况下,仍然稳定地输给 Zen2。
带宽
带宽对于向量化、多线程应用程序尤其重要。3A6000 在很大程度上继承了它前身的内存层次结构,但龙芯再次在各个地方进行了改进。
3A5000 已经拥有与 Intel 的 Skylake 或 AMD 的 Zen2 相似的每周期 L1d 带宽。3A6000 通过加倍写入带宽进行了改善。基本上 3A6000 的 L1d 可以每周期完成两次 256 位访问,无论是读取还是写入。
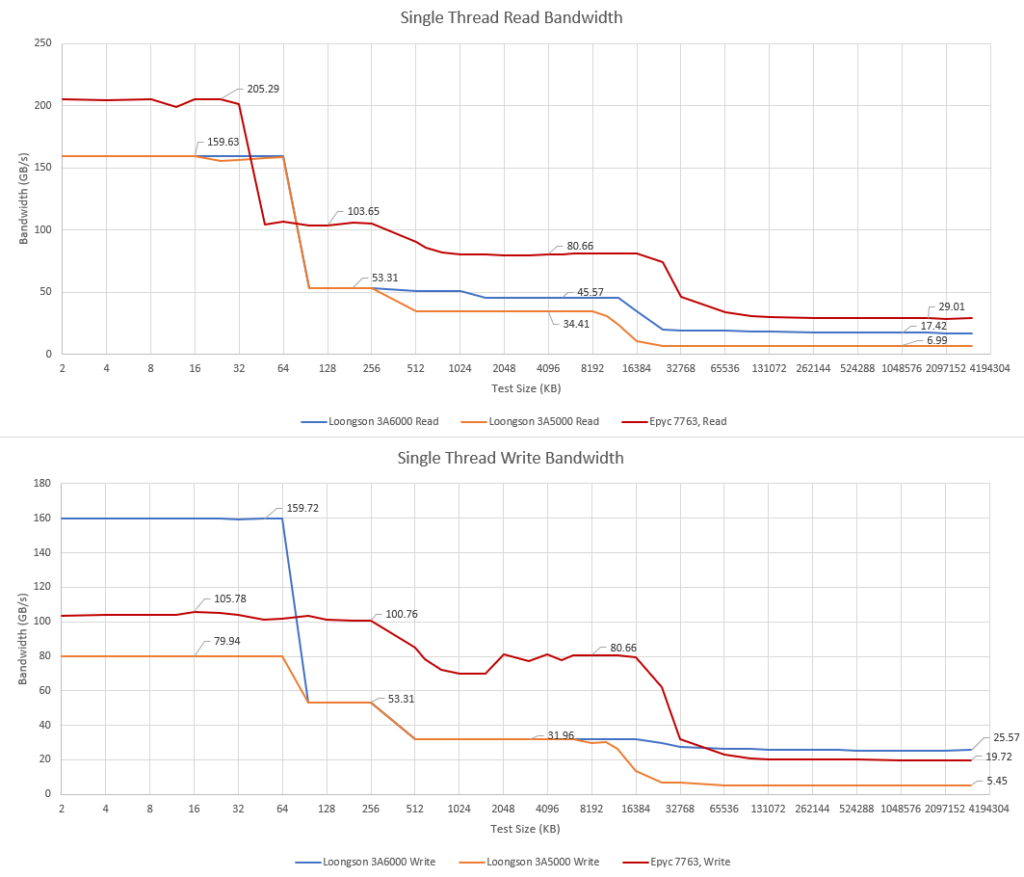
因此,尽管时钟频率较低,3A6000 拥有令人印象深刻的 L1d 写入带宽。LA664 因此成为了和 Golden Cove 一样唯二的两个具有每周期 512 字节存储带宽的消费级 CPU。
LA664 的 256KB L2 表现与其前身基本类似,每周期读带宽为 21-22 字节,写带宽相同。因此,3A6000 的 L2 带宽仍然低于 AMD 或 Intel 最近的任何 CPU。与 Intel 的 CPU 相比差距特别大,后者有每周期 64字节的 L2 带宽。
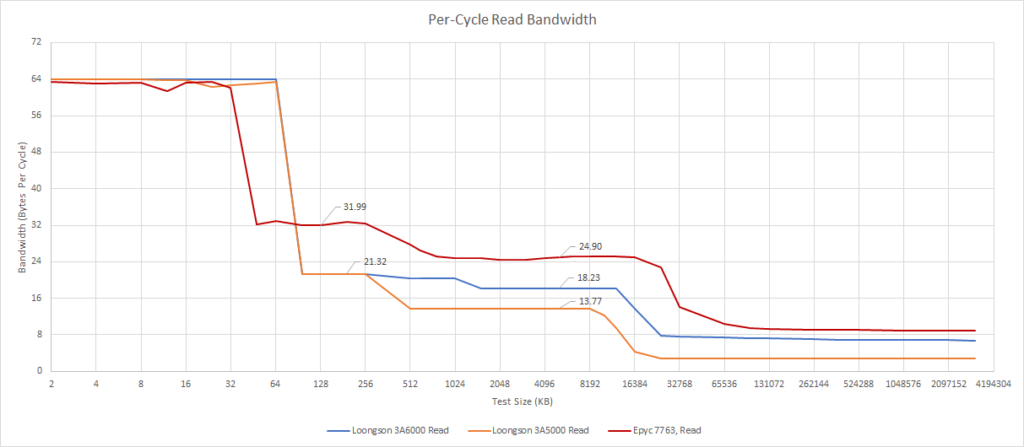
在 L3 中,LA664 比其前代增加了 33% 的带宽。每周期从 L3 获取 18.7 字节的带宽让龙芯可以对抗较老的 Intel CPU,但 AMD 特别强大的 L3 仍然遥遥领先。
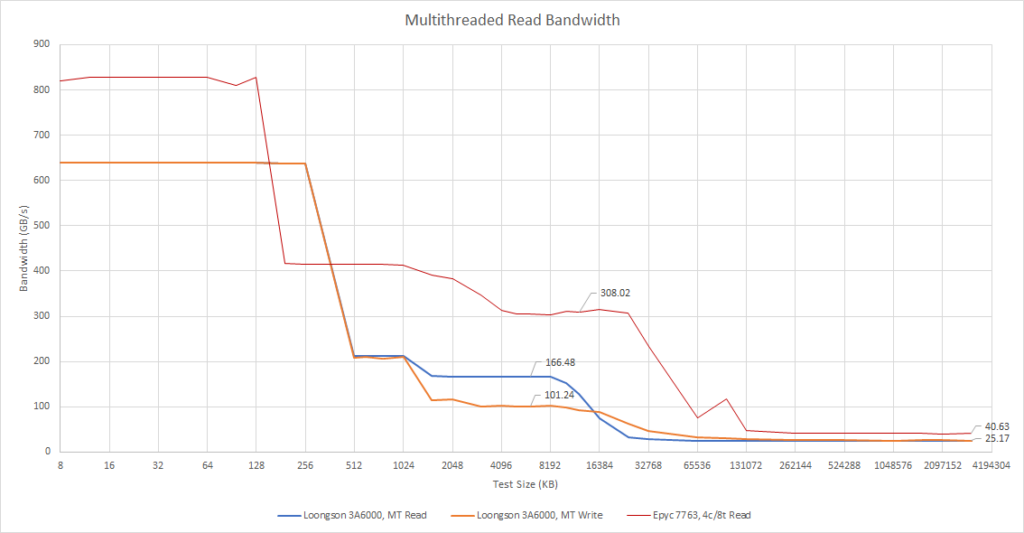
设计共享缓存引入了额外的挑战,因为缓存带宽在服务多个客户时还要增加。当所有硬件线程都活跃时,3A6000 可以给每个核心每周期提供 16.55 字节。这比单个核心在没有其他核心竞争的情况下只少了一点点,是非常好的表现。旧的 3A5000 在所有四个核心加载时只能为每个核心每周期提供 10 字节多一点,与单一核心的 13.7 字节相比。这表明 3A5000 的 L3 结构存在竞争,而 3A6000 在很大程度上解决了这个问题。AMD 在多个核心一起冲击缓存时再次提供了出色的每核心 L3 带宽,每核心每周期超过 24 字节。
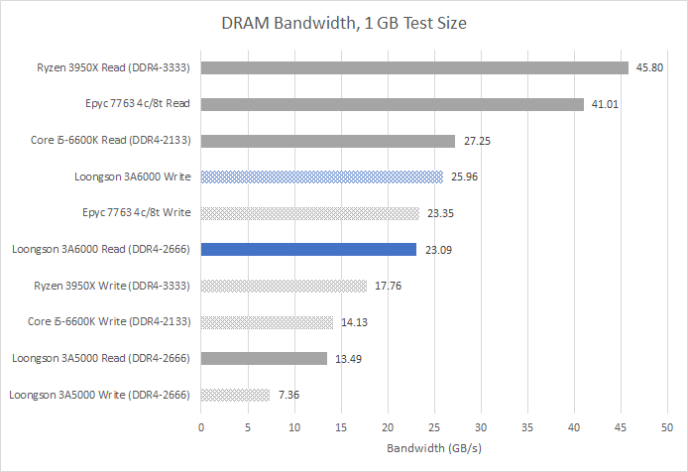
龙芯的 3A5000 有一个极其糟糕的 DDR4 控制器。幸运的是,3A6000 有一个更好的控制器。技术上它支持 DDR4-3200,但我们在使用这个速度运行双通道内存时无法稳定启动。当装配双通道 DDR4-2666 时,3A6000 实现的 DRAM 读带宽大致与 Core i5-6600K 相当。这个酷睿芯片的第一代 DDR4 控制器只能在完全稳定的情况下处理 DDR4-2133 的速度(至少在我的样本上是这样),但仍然比 3A6000 用更快的内存实现更好的 DRAM 读带宽。

尽管 3A6000 的 DRAM 读取性能一般,但它也有一个小 trick:当检测到缓存行被完全覆写而且没有对其先前内容的依赖时,可能会避免获取这个缓存行的所有权。这可能有助于某些访问模式,但好处可能会受限,因为程序通常有更多的读取而不是写入操作。
核心到核心延迟
这个测试使用原子比较和交换操作在核心之间传递值。
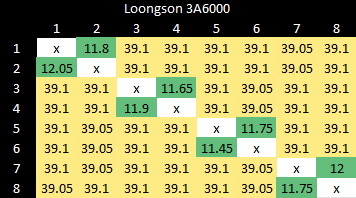
龙芯的性能没有带来任何惊喜(惊吓),这是一件好事。
结语
龙芯的工程师有许多值得骄傲的地方。设计与 Zen2 相当的分支预测器并不容易,考虑到龙芯在 3A5000 中的表现,这一成就更显卓越。同样地,SMT 非常难以实现正确。龙芯在大幅扩展 3A5000 的乱序引擎和修复其 DDR4 控制器的同时,设法完成了这两件事。这些巨大的性能提升使 LA664 与 Zen1 在单核性能上相当。
3A6000 是中国为使其经济减少对外国 CPU 依赖所做努力的一部分。在这方面,3A6000 是向前迈出的一步。Zen1 在今天仍然非常可用,所以中国消费者可能会发现 3A6000 的性能对于轻量级日常任务已经是可以接受的了。龙芯的软件生态系统比性能更影响芯片的可用性。
但龙芯还有一个成为世界级 CPU 制造商的次级目标,与西方公司如 Intel 和 AMD 并肩。在这方面,他们还有很长的路要走。Zen1 级别的单线程性能值得赞扬。但我们必须记住,Zen1 之所以能够从 Intel 那里夺取市场份额,是因为它将便宜的的 6 核和 8 核产品带入了消费者平台,而不是因为它能够以核心对核心的方式赢得 Skylake。3A6000 只是一个四核产品,因此缺少了 Zen1 最大的优势。
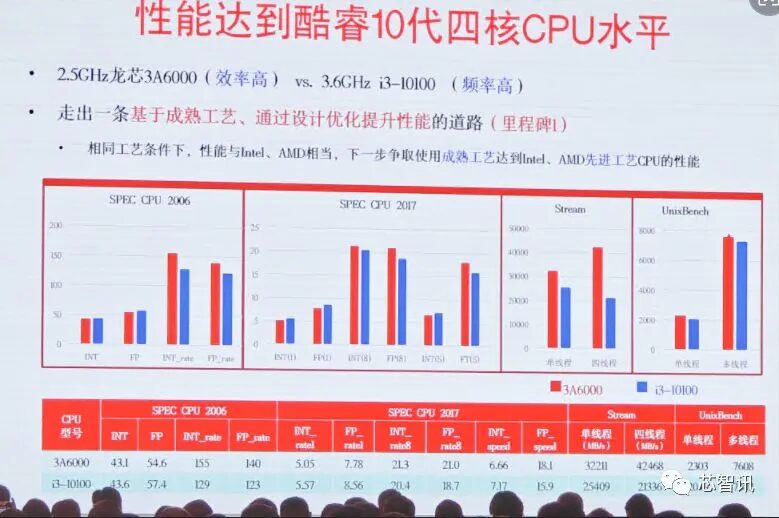
龙芯还将 3A6000 与 Intel 的 Core i3-10100 相比较——一个带有 6MB 缓存和 4.3 GHz 睿频时钟的四核 Skylake 产品。虽然从名义上看是第 10 代产品,i3-10100 更类似于 2015 年的 Core i7-6700K。Intel 的第 10 代更为人所知的是将 10 核 CPU 带入消费者阵容,而 6 核和 8 核构成中端产品。除了更多核心,像 i5-10600K 和 i7-10700K 这样的部件还享有更高的睿频频率。3A6000 将无法与这些产品竞争。针对同一时代的 Zen2 产品,龙芯也将遇到挑战。我们已经看到,3950X 在相同核心数量的测试中轻松超过 3A6000。当 Zen2 的更多核心开始发挥作用时,这一差距将只会变得更大。
今天,Intel 的 Golden Cove 衍生产品和 AMD 的 Zen4 在 3A6000 之上还有更大的领先优势。四核产品在 AMD 和 Intel 的消费者产品阵容中已经几乎消失。龙芯的 3A6000 可能是我们从中国看到的最有前途的 CPU,远比围绕 A72 进行的笨拙尝试更加令人兴奋。但龙芯的工程师们仍有大量工作要做。我们期待看到他们接下来能够实现什么。
本文翻译自 ChipsAndCheese,原文为英文,原文链接:https://chipsandcheese.com/2024/03/13/loongson-3a6000-a-star-among-chinese-cpus/ 原作者:clamchowder
本文中文翻译首发自我的博客 https://blog.eastonman.com/blog/2024/03/loongson-3a6000-a-star-among-chinese-cpus/ ,翻译已取得 ChipsAndCheese 编辑/原作者授权。因英文原文无公开的授权协议,本译文也禁止转载,如需转载请先联系我或 ChipsAndCheese。
