预计阅读时间: 24 分钟
本文大部分翻译自 ChipsAndCheese,添加有个人理解和资料补充 ,原文为英文,原文链接:https://chipsandcheese.com/2023/09/01/hot-chips-2023-ventanas-unconventional-veyron-v1/ 原作者:chlamchowder
本文中文翻译首发自我的博客 https://blog.eastonman.com/blog/2024/02/hot-chips-2023-ventanas-unconventional-veyron-v1/ ,翻译已取得 ChipsAndCheese 编辑/原作者授权。因英文原文无公开的授权协议,本译文也禁止转载,如需转载请先联系我或 ChipsAndCheese。
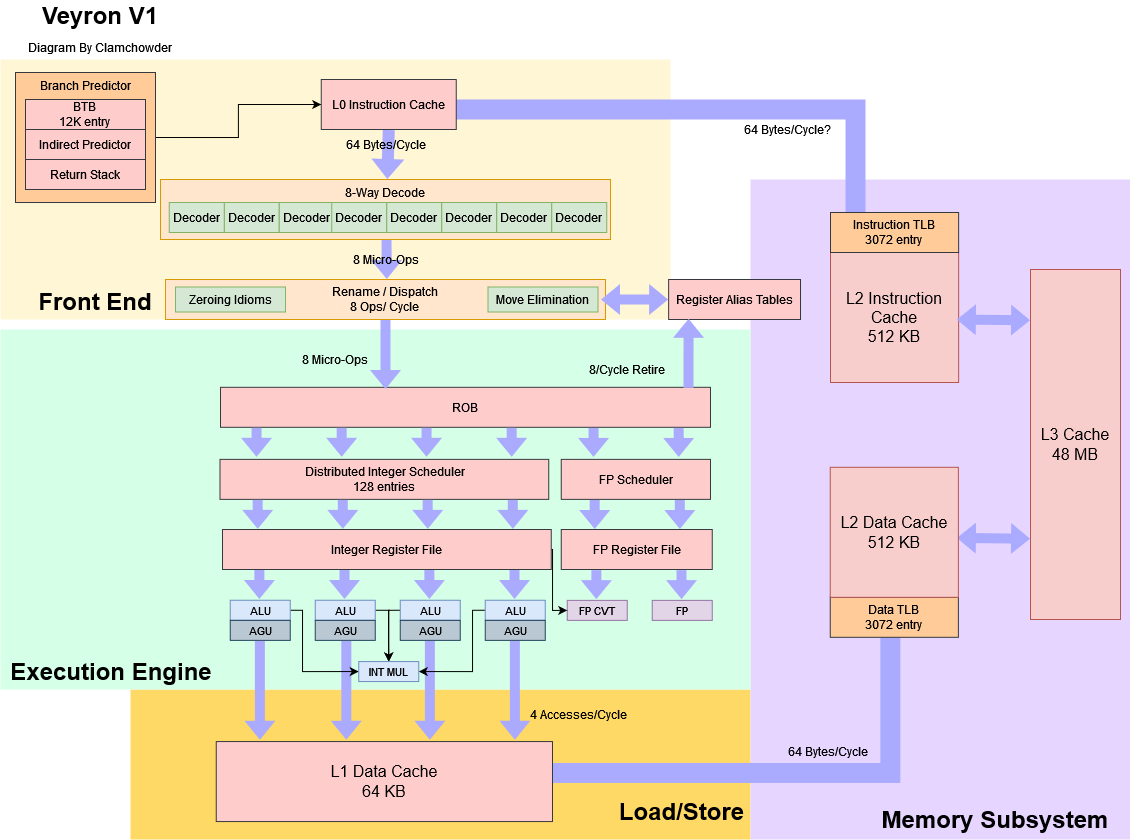
总体设计
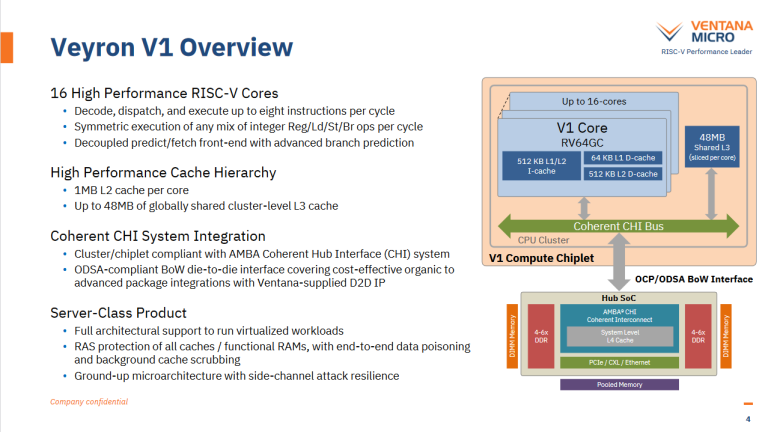
Veyron V1 是一个八发射的乱序核心(这里一般指重命名/分派宽度)。分支误预测惩罚是 15 周期,乱序调度队列容量十分可观。与 ARM 和 SiFive 的设计类似,Veyron V1 以适中的时钟频率换取较低的面积和功率,这使它能扩展到非常多的核心。Ventana 给 Veyron V1 的目标频率是 3.6GHz,但 Veyron V1 还可以降频以减少功耗,例如在 2.4GHz 时,核心的功耗少于 0.9W。
译者:总体来说 8 宽度的重命名可以做到 3.6GHz 的最高频率,2.4GHz 下功耗小于 0.9W,这个设计能力并不算最好,但鉴于 RISC-V 各家都没有太多的基础,在较短时间内能迭代到这样的效果也属于不错了。
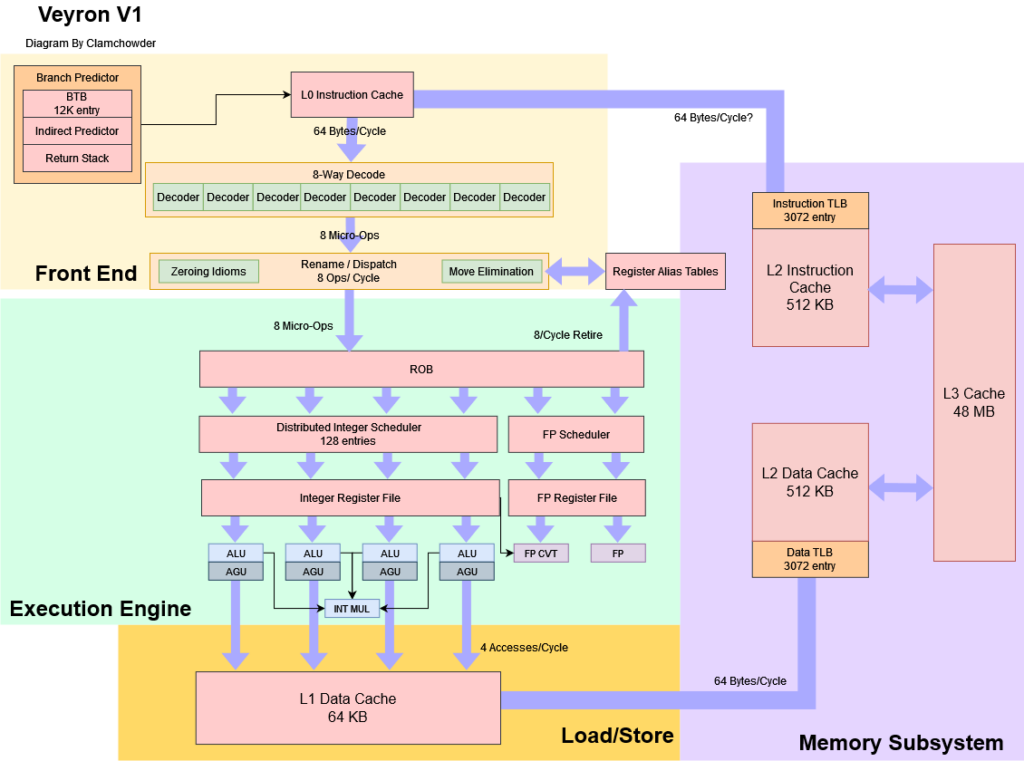
流水线设计
乍一看,Veyron V1 的流水线深度可能会显得比较深(15 周期的分支误预测惩罚)。作为比较,AMD Zen4 的最小分支误预测惩罚是 11 周期,ARM 的 Neoverse N2 的流水线深度是 10 周期(我们假设 ARM 在之前的 HotChips 演讲中提到的流水线深度就是指最小分支误预测惩罚)。
Ventana 表示他们新版的 V2 架构改善了分支误预测惩罚,在他们的演示中也提到了一点。在整数执行阶段1(IX1)检测到的误预测会触发在RPS(Restart Pipe Start)阶段的流水,和 IX1 重叠。这个周期离标记为 PNI 的预测流水有两个周期的距离。PNI大概率表示 Predict Next IP,意思是生成 Next Instruction Pointer 的地方。

通过比较实际的分支方向与预测的方向或比较跳转的目标,可以检测出分支误预测。如果直接将真实的目标地址或正确方向反馈到分支预测器中,应该能让流水线在 PNI 之后立即重新启动,将误预测惩罚减少两个周期(降至13个周期)。
分支预测器:单级 BTB
像其他一些现代 CPU 一样,Veyron V1 使用了解耦前端(分离式前端)。同时,解耦前端的分支预测结果也充当了准确的指令预取器。为了最大限度地利用这种技术,预测器必须能够同时且准确地跟踪多个分支目标。因此大的分支目标缓冲(BTB)对于分支预测器而言至关重要,这可以让分支预测器无需从指令缓存中获取指令后才能解码出跳转的目标,降低了延迟。
但是无论是存储分支目标还是直接存储指令数据,大而快的缓存都难以制造。因此现代 CPU 一般选择多级 BTB。通常快速的一级 BTB 能够背靠背地预测跳转的分支,而较慢的下级 BTB 则有助于保持在较大分支足迹下的良好性能。像 Intel 就有 3-4 级的 BTB 结构。
尽管在速度、容量和复杂性之间通常需要权衡,Ventana 说“我全都要”。V1 有一个 12K 项的巨大单级 BTB,和一个“单周期 next-line 预测器”。与 Berkerly 的 BOOM 相似,“next-line 预测器”包括有 BTB 查询,因此如果按照 Ventana 演示的说法,12K 项的 BTB 是可以做到背靠背地预测跳转分支的。这是相当了不起的成就,这让 V1 能够以最小的吞吐量损失处理非常大的分支足迹。对比之下,以 Intel 的 Golden Cove 为例,它也有一个 12K 条目的 Last-level BTB,但是延迟为三个周期。
译者:这可能和 Intel 的目标频率较高有关系,但是 Ventana 的单级 BTB 设计还是不太寻常,也许和尚未完全挖掘工艺制程的潜力有关。我猜测 Ventana 使用这样的设计仅是因为没有做更好的设计,巨大的单级 BTB 还会带来比较大的功耗开销,毕竟每周期都需要开启。结合 Ventana 提供的功耗数据,我觉得他们的低功耗设计还有很大的空间。

如果 BTB 未提供正确的目标,V1 声称能做到“three-cycle redirect on mispredict”。这可能意味着静态预测器(预译码)距离指令取指有三个周期,或者在解码的第一周期,因为 V1 的指令缓存延迟为两个周期。在有这么大的 12K 项 BTB 的情况下,这样的静态预测器(预译码)重定向应该会比较罕见。
前端:512KB L1/L2指令缓存
除了 BTB 的层级,Ventana 也减少了指令缓存层级。Veyron V1 有一个大的 512KB 指令缓存,充当 L1/L2 指令缓存的角色。一个小型循环缓冲区位于指令缓存的上方,但这主要是对密集循环的 Power 优化。V1 预计大部分时间都会从 512KB 的 L1/L2 缓存中获取指令。
Veyron V1 的前端设计适合于大指令足迹的软件,这些足迹溢出了我们通常看到的 32KB 或 64KB 的指令缓存。在这种情况下,其他 CPU 会浪费功耗和时间在检查 L1i 上,并需要在两级缓存之间交换指令数据。
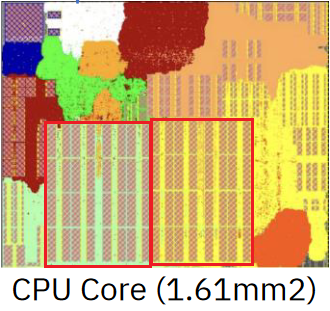
V1 的设计使用强制性的 L2 分区,牺牲了我们在其他 CPU 上看到的缓存容量灵活性。如果程序是少量代码在大量数据上循环,一个统一的 1MB L2 可以几乎使用其所有容量来存储数据。或者,如果一个应用的数据足迹很小,但代码足迹很大,则可以为指令缓存分配更多容量。
如果 Ventana 尝试使用一个统一的 L2 缓存,取指的流量可能会与数据侧的 L2 访问引起冲突。CPU 的前端是缓存带宽的重要消费者,因为每条指令都必须经由前端访问下级缓存系统来获得,但不是每条指令都会有数据侧的内存访问。此外,不完美的分支预测会导致在一个误预测分支之后的指令有多于一个的前端内存访问(因为第一次尝试取错了东西)。假设一个统一的 1MB 缓存充当 L1/L2 指令缓存和 L2 数据缓存,可能会遇到指令和数据访问之间的冲突。
因此,Veyron V1 的 L2i 和 L2d 缓存各自需要足够的容量,以便在广泛的工作负载中都能充当有效的中层缓存。一个 512+512KB 的 L2 设置无疑会提供比统一的 512KB L2(如 AMD 的 Zen1 到 Zen3 中的)更好的缓存容量,但与 AMD 的 Zen4(以及一堆 ARM 的设计)上的统一 1MB L2 相比,可能会比较差。
译者:这样的设计也比较激进,这种设计的思路来源是依靠 BTB 存储信息的密度优势,减少靠近流水线部分的 memory 数量,然后依靠预取来掩盖较远的 L2 的延迟。但是这样设计也有很多不好解决的问题,例如下面提到的非对齐取指。
非对齐取指支持
如果你仔细看 Ventana 的演示文稿,他们宣称支持”每周期最多完整 64B 的的非对齐取指”。通常来说前端缓存访问是对齐的,也就是说向指令缓存发送的地址中最低的几位是零。例如,一个 32B 对齐的取指会隐式地将五个最低地址位归零。
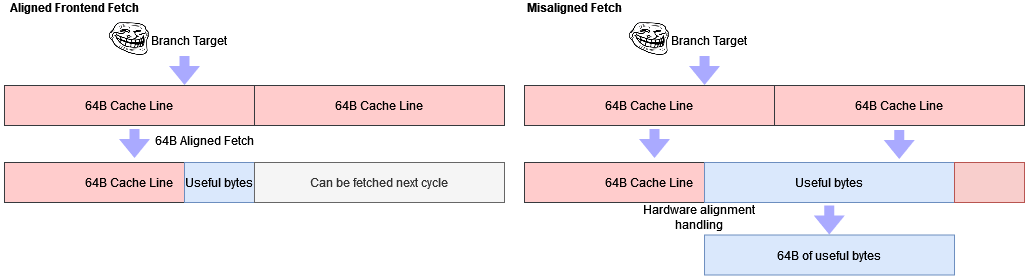
支持非对齐的取指是挺不错的,因为即使分支跳转到一个缓存行的中间,也可以维持高取指带宽。但不知道 Ventana 是如何实现这一点的。通常,非对齐访问是通过在底层进行两次访问并合并输出的数据来处理的。数据缓存通常有足够的 SRAM 带宽,可以每个周期这样做。但是一个指令缓存能够做到,尤其是一个512KB的缓存,感觉有点过分。
译者:这里就发现 Ventana 这种设计的问题了,目前各家 CPU 支持非对齐的取指都是通过较细粒度的分 bank 来实现,比如 Apple 和 AMD。然而 L2 通常需要追求高密度,做太细粒度的分 bank 不太合适。观察 Ventana 放出的 floorplan,他们 L2 的分 bank 粒度也较粗,猜测可能就是 64B 或者更大。这样会带来新的功耗问题,因为每周期都需要访问两个这么大的 SRAM,还需要在前端处理 128B 的裁切,这个开销可不小。这个其实也和 Ventana 给出的功耗数据相印证,说明他们的功耗还有很大的优化空间。
巨大的单级 TLB
接着减少缓存层级的主题,Ventana 选择了单级指令和数据 TLB。每个都有 3K 项,与其他家的大 L2 TLB 容量相匹配。作为比较,AMD 的 Zen4 有一个3072 项的 L2 dTLB,而英特尔的 Golden Cove 有一个 2048 项的 L2 TLB。 TLB(地址翻译缓冲器)是虚拟地址到物理地址转换的缓存。在你的电脑上运行的程序通过虚拟地址访问内存,这些地址通过操作系统管理的页表映射到物理地址。通常,每个内存访问都需要一个地址转换,因此 CPU 有一个小但高度优化的L1 dTLB,它记住了最常访问页面的转换。
在指令方面,512KB 的 L1/L2 指令缓存的访问需要同时访问 L1 iTLB。这意味着大多数指令访问将会引起大 iTLB 的查找。因为代码通常顺序执行直到遇到分支,所以一个单读口的 TLB 应该足以满足多条指令。
在数据方面,Ventana 删除了L1 dTLB,并且采用了虚拟地址 L1 DCache。主 TLB 在通向 L2 的路上被访问,使其不需要像传统L1 dTLB那样对延迟和功耗敏感。
译者:这个其实也很不利于功耗的控制,Ventana 看起来就和香山的开发团队一样,首先追求性能,然后才是功耗面积等。这也不难理解,毕竟现在在 PPT 上性能最吸引人。
VIVT 的 L1 数据缓存
Veyron V1 有一个 64KB 的数据缓存。它是虚拟地址索引和虚拟地址标记的(VIVT),与其他CPU中使用的虚拟索引、物理标记的(VIPT)缓存不太一样。VIPT 缓存的重要之处在于它的行为和纯粹的物理地址缓存是一样的。传统上,虚拟地址的缓存有很多缺点:它们会在上下文切换或 TLB 维护操作时被刷新,因为更改虚拟地址到物理地址的映射意味着一个虚拟地址的缓存的内容不再是最新的。

然而,Ventana 尝试通过在 L1d 标签中跟踪 ASID 来避免这些缺点。这让他们可以避免在上下文切换时刷新 L1 数据缓存。此外,L1d 可以处理多个虚拟地址映射到同一个物理地址的情况。也许 V1 在 L2 TLB 中记录一定数量的 VA 到 PA 别名,并在 snoop 请求出现时一次性使这些别名失效。
V1 的 L1d 仍然有四个周期的延迟,与 AMD 和 ARM 近期的 CPU 非常相似。他们没有从使用虚拟地址的 L1d 中获得任何延迟优势,但他们避免了维护 L1 dTLB 的功耗和面积开销。Ventana 在使用 VIVT 缓存上面临不少质疑,但我认为他们会没问题的。他们显然已经努力避免了虚拟地址缓存带来的最大问题。即使这种做法最终的缺失率高于同等大小的 VIPT L1d,那么他们 L2 的命中延迟其实也相对较低,只有 11-12 个周期,不会有太大的问题。
译者:这个 VIVT 缓存肯定是引起很多质疑的,因为历史上使用 VIVT 缓存的设计好像都活得不久。现在的操作系统似乎也很少认为修改页表会引起数据缓存上的开销。更别说这种设计还需要新的一致性处理机制,我猜测他们的验证成本会比较高。
译者:我还是很难理解 Ventana 这个减少各种 memory 的层级的设计,感觉并没有给他们带来什么可观的好处。如果他们的 L1d 延迟能进一步降低(降低一周期),我觉得用 VIVT 缓存 + 单级 TLB 就可以说是值得的。但是他们大费周章最终并没有体现在性能上,这就让我感觉不太值得。也许他们这个结构还有降低一拍的潜力,只是还未解决工程上的问题。
乱序执行引擎
通常 CPU 会有多种执行端口。这是因为不同的执行单元专门用于不同的操作,而且足够的执行端口必须为 CPU 可能遇到的不同指令组合提供服务。Ventana 选择使用更少、更灵活(功能更多)的端口。尽管重命名宽度是8,Veyron V1 只有四个整数和访存共用的执行端口。直觉上,核心的吞吐量会受到缺乏执行资源的限制。
然而,即使前端的宽度很宽,执行资源很少被持续完全利用,因为在今天的高性能 CPU 中,吞吐量通常受到内存延迟的限制。Sandy Bridge 是一个 Intel 的例子,它的端口数量也相对较少。即便有时会遇到端口争用,也是因为某些工作负载压迫了特定端口后面的执行单元,而不是CPU整体的执行端口数量不足。
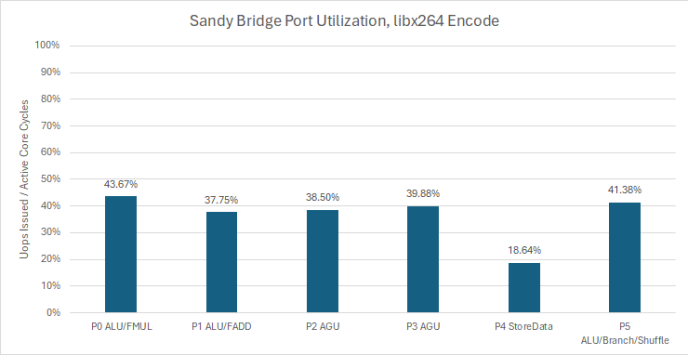
因此,Veyron 出于减少功耗和面积的考虑,选择使用四个被充分利用的整数执行端口,而不是更多利用率较低的执行端口。

虽然 Veyron 的执行端口布局在 HotChips 上肯定引起了一些关注,但我不认为它有什么不寻常的。其他 CPU 通过让端口服务不同的指令类别也减少了执行端口的数量。英特尔长期以来将浮点和整数执行单元放在同一个端口后面。富士通的 A64FX 也有两个端口同时服务 AGU 和 ALU。
这种方法的好处也很明显。
(Zen4 的向量寄存器堆)自寄存器堆的面积主要受读写端口的宽度和数量限制,而不是存储的限制以来,仅有很小的增长。
Kai Troester 在 HotChips 2023 上,关于 Zen4 的 AVX-512 实现
更多的端口意味着要么有更多的调度队列,要么使用更复杂的调度器,可以每周期选择多个操作。寄存器堆的面积是另一个考虑因素,更多的执行单元/发射端口就需要更多的寄存器堆端口来满足它们。避免这种面积增大是一个明智的举动。
面积
面积对 Ventana 来说也是重要的,因为他们的目标是高核心数量,减少面积有助于降低成本。Veyron V1 的面积小于 AMD 的 Zen4c 和 ARM 的 Neoverse V2。Ventana 平衡面积的设计决策在此起了作用,但 Veyron V1 为了减少面积使用也牺牲了性能:它不支持向量扩展,仅有一个标量浮点流水。相比之下,AMD 的 Zen4c 具有非常高的向量和标量浮点吞吐量。与 Neoverse V2 相比,Veyron V1 的 L2缓存容量较小。Ventana 无疑实现了良好的核心面积效率,但其非传统的设计决策使它至少在面积方面不是 Game Changer。

ARM 的 Neoverse N2 是另一个有趣的比较。它不如 Veyron V1 宽,具有较小的 BTB 和 TLB。V1 可能在整数应用上表现得更好,特别是如果那些代码具有较大的指令侧内存占用。但 N2 也有优势,比如一个非常基础的 2×128b 向量流水配置。
Cluster 面积
核心面积只是一部分,最近的手机和服务器 CPU 在互连和缓存这样的外围逻辑上花费了大量的面积。AMD 的 Bergamo 可以作为一个有趣的比较,因为 Ventana 计划使用类似 AMD 的 hub-spoke chiplet 配置来扩展到大量的核心。也就是说,Veyron V1 和 Zen4c 都使用计算模块连接到中心 IO 模块的这种封装形式。
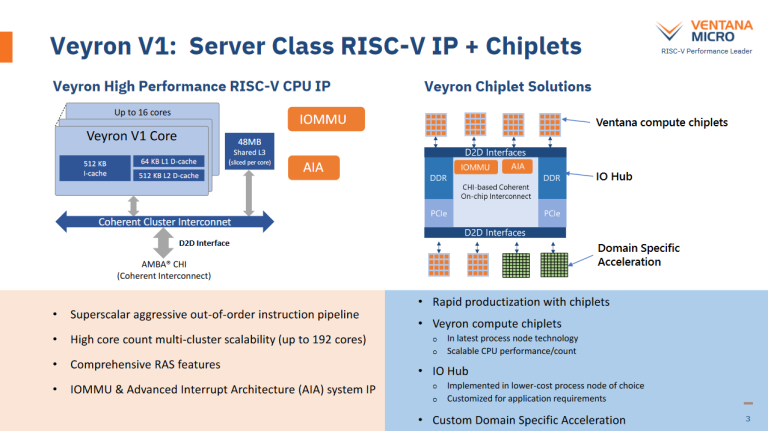
Ventana 在他们的 HotChips 演讲中提供了一个 16 核心 Veyron V1 Cluster 的图片,以及在 TSMC 5nm 工艺上的面积数据。AMD 也在他们的演讲中提供了一个 Zen4c 16 核心 CCD 的照片。在这里使用了 Fritzchens Fritz 的 69.49 平方毫米的数据作为 Zen4 CCD 的大小用于面积比较,并假设 Zen4c 的 CCD 占用类似的面积。

乍一看,具有缓存和支持互连逻辑的 16 个 Veyron V1 核心相对于 AMD 的 Bergamo 有轻微的面积优势。然而,仔细查看 die shot 显示,Ventana 没有在他们的图片中包含芯片到芯片的接口。这种接口将占用大量的面积。

因此,Veyron V1 的计算模块大小可能与 AMD Bergamo 的不相上下。Veyron V1 每核享有更多的 L3 缓存容量:每核3MB,相比之下 AMD 是每核2MB。Ventana 的 Cluster 内互连还覆盖了 16 个核心及其关联的 L3 Slice,为任意核心提供 48MB 的 L3 容量。对 AMD 来说,他们的 Zen4c 核心拥有更灵活的统一 L2 缓存和更强大的浮点和向量执行能力。
Cluster 内互连
Ventana 使用类环形的互连。他们在演示上说有两个环,但在 2.5GHz 频率下 160GB/s 的对分带宽意味着每周期 64B。如果环每周期可以传32B,那么可能就只有一个环,然后环两侧都在传输。

也许它是双环配置,然后每周期只能移动 16B。我不完全确定 Ventana 的互连在这里是什么样子,但基于环的互联往往能提供相当好的 L3 性能。希望Ventana 在这里做得很好,因为他们的分离的 512+512KB 的 L2 设计可能意味着 L3 看到的流量比具有 1MB 统一 L2 的设计更多。
写在最后
Veyron V1 有一套非常独特的设计决策。偏离常规是有风险的,因为历史上工程师已经弄清楚了在 CPU 设计上什么有效以及什么无效。这就是为什么成功的 CPU 有很多共同的设计特点。Ventana 似乎做得相当不错,他们没有落入任何明显的漏洞。他们通过硬件别名处理和 ASID 过滤缓解了 VIVT 缓存带来的问题。他们的分离 L2 设计在指令和数据两侧都有足够的缓存容量。他们大型的单级 BTB 和 TLB 要么具有足够低的延迟不会阻碍性能,要么不在性能关键路径上。
尽管 Veyron V1 是 Ventana 的首款设计,它有望成为在标量整数应用领域的强力竞争对手。但 Ventana 在处理吞吐量密集型应用时将遇到更大的挑战。由于 V1 缺乏向量单元,即便 V2 搭载了向量单元,RISC-V 生态系统的成熟程度仍旧落后于 ARM,这就需要软件来支持 RISC-V 的向量扩展功能。许多吞吐量受限的软件如视频编码器、渲染器和图像处理应用是由社区维护的,而不同社区的对支持新指令集的优先程度不同,这使得对新指令集扩展的支持通常进展缓慢。ARM在努力成为x86可行替代品的过程中已经遇到了软件支持的难题,而RISC-V在这方面面临的挑战则更为严峻。
译者:Ventana 这个核心从开发的角度上来说感觉与香山处在类似的阶段,但是商业化上比香山做得更早更好。但是不知道是不是因为不寻常的设计决策拉长了验证周期,感觉 Ventana 的 IP 在进入硅的速度上比 SiFive 慢一点。
我们要感谢 Ventana 为他们的 Veyron V1 核心整理了非常好的演讲,并期待看到该公司在即将推出的 V2 设计上做了些什么。
本文大部分翻译自 ChipsAndCheese,添加有个人理解和资料补充 ,原文为英文,原文链接:https://chipsandcheese.com/2023/09/01/hot-chips-2023-ventanas-unconventional-veyron-v1/ 原作者:chlamchowder
本文中文翻译首发自我的博客 https://blog.eastonman.com/blog/2024/02/hot-chips-2023-ventanas-unconventional-veyron-v1/ ,翻译已取得 ChipsAndCheese 编辑/原作者授权。因英文原文无公开的授权协议,本译文也禁止转载,如需转载请先联系我或 ChipsAndCheese。

路过,膜拜下大佬哦