
预计阅读时间: 24 分钟
Branch Prediction Is Not A Solved Problem
–Intel
我从 2022 年底开始在香山开源高性能处理器团队里实习,到现在已满一年了,一直主要负责前端取指模块中分支预测单元的改进。到了年底了,略有一点空闲时间来写一下目前为止在分支预测方面的见闻。
本文假定读者对数字电路设计和高性能 CPU 设计都有一定了解,知道什么是“分支预测”以及“分支预测”对于高性能 CPU 来说的重要意义,如果你完全不了解这部分内容,但又感兴趣的话,建议先去看一些相关的基础书籍和文章。
另外本文基本上仅探讨条件分支的预测,也即只进行 T/NT 的方向预测,其他类型的分支如果大家感兴趣我以后再写。
希望本文能被一些刚参加完龙芯杯,或者通过一生一芯学习的同学阅读。如果想要尝试做分支预测器方面的工作,或者到香山前端团队来实习,那么在雄心壮志开始准备大战预测算法提高准确率之前,请先停下来了解一下真正的高性能处理器设计对分支预测的需求。
分支预测发展历史
最古老的分支预测方法就是饱和计数器,这里假设读者已经充分了解什么是饱和计数器和用饱和计数器来预测分支的方法了。
饱和计数器只能作出偏向性的预测,并不能充分利用单个分支内部和分支之间的关联信息,因此很快就发展出了能够利用分支历史信息的预测器,例如 GShare 预测器:
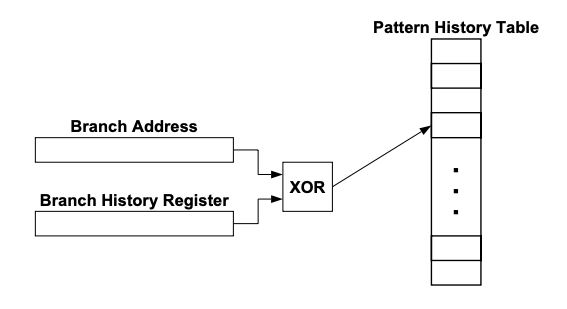
来自 An Analysis of Correlation and Predictability:
What Makes Two-Level Branch Predictors Work
GShare 预测器将分支的 PC 与一个全局历史寄存器 XOR 以后作为 index 来选择 PHT 中的一个饱和计数器,然后使用这个计数器给出预测方向,更新时同样也通过同样的方式索引到同一个饱和计数器并更新。
这种方式将不同全局分支历史下的同一条分支的预测分给了不同的饱和计数器,使得 GShare 预测器能够区分不同的历史。这样做带来的第一个好处是能够正确预测循环退出了。
另一个好处是,分支之间的相关性可以得到有效利用,下图是常见的分支间相关性的例子

以上的两个例子恰好对应局部分支历史和全局分支历史。循环退出的预测只需要单个 PC 的历史就可以解决,而分支间相关的例子则必须要全局的分支历史。可见不同的分支需要的历史是不同的,由此发展出了锦标赛预测器,由局部历史和全局历史的两个预测器分别独立预测,然后再由一个饱和计数器构成的选择结构选择使用哪个子预测器提供的方向预测。著名的 Alpha 21264 处理器就是使用了锦标赛预测器。
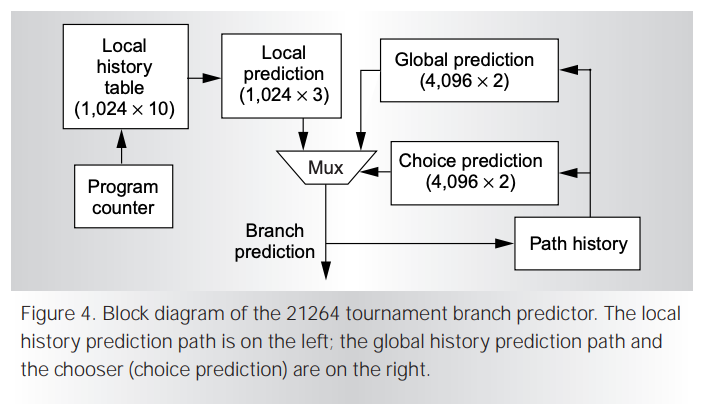
Alpha 21264 是经典的超标量乱序处理器,它的论文值得大家一看 The Alpha 21264 microprocessor
现代分支预测算法
Branch prediction research is basically about separating easier and more difficult branches, and using a simple predictor for the easy branches and a complex predictor for the difficult ones.
— Onur Mutlu (Computer Architecture and Digital Design, ETHZ)
现代的分支预测器算法只有一种——TAGE,几乎所有的学术研究和商业高性能处理器都使用 TAGE 或者 TAGE 的变种。TAGE 预测器是最早在 2006 年由 Andre Seznec 提出的,提出当时即获得当届分支预测锦标赛冠军。然后接下来直到 2016 年的所有分支预测锦标赛都由TAGE预测器的变种获得。
我在 2022 年参加龙芯杯比赛复现 TAGE 预测器的时候,对 Mutlu 教授在课程中的这句话感受颇深。分支本身的预测难度不尽相同, 如果使用复杂的分支预测器预测简单的分支,那么大概率会浪费存储空间。TAGE 预测器的设计和这一个思想不谋而合,它使用多个不同历史长度的子预测器,并且使用一套机制自动地在这些子预测器中分配表项。这样能够做到使用短历史预测简单分支,长历史预测复杂分支,同时也能够避免存储空间的浪费。
以下是 TAGE 预测器的框图
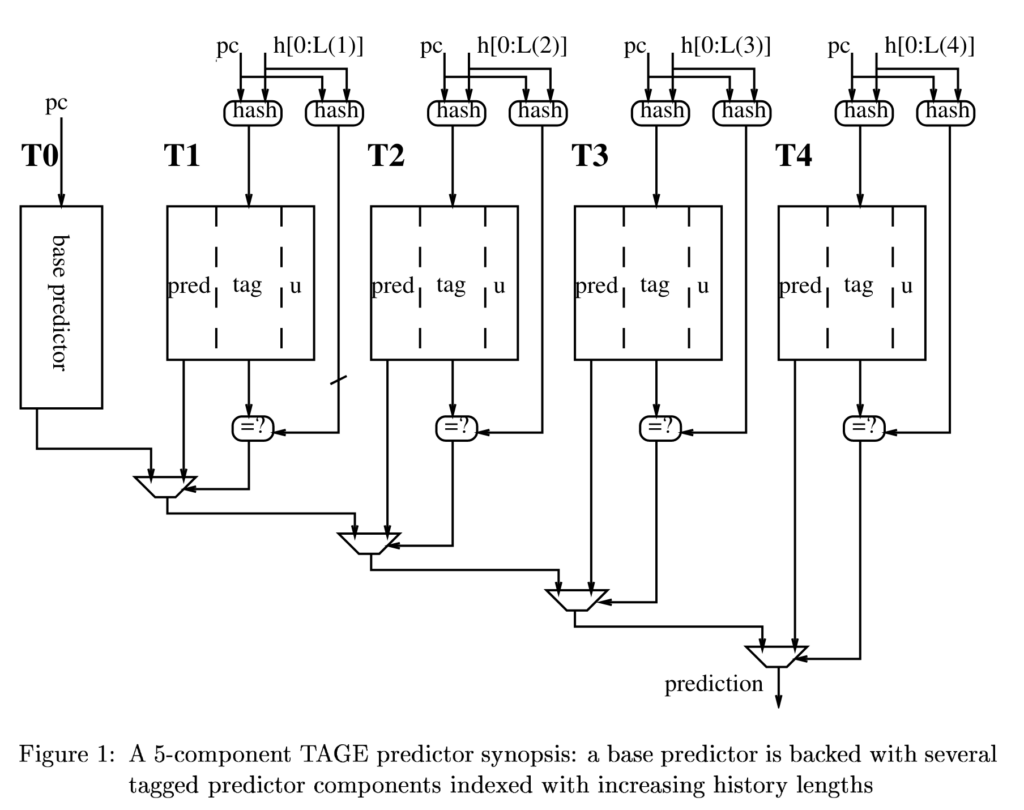
对预测机制细节感兴趣的读者可以参考原论文 A case for (partially) TAgged GEometric history length branch prediction
解耦合前端与覆盖重定向
像 TAG E这种复杂程度的预测器是没有可能当拍就能得到预测结果的,本文撰写的时期(2023年)附近的半导体工艺对于 SRAM 微缩已经遇到了困难,目前 SRAM 访问就需要接近一个时钟周期或者一个完整的时钟周期了。另外考虑到每个 PC 都访问复杂预测器在功耗上的开销,商业处理器也很少做非常激进的省拍策略(如提前流水等)。
故 TAGE 预测器的返回结果到下一次的预测之间就出现了空拍,这是难以接受的,对性能的影响非常大。所以很自然的就出现多级预测器——覆盖重定向这种策略。这种设计一般使用简单的预测器进行 zero-bubble 的预测,然后再使用复杂预测器对简单预测器的结果进行验证,如果预测不一致,就会发出一个前端重定向,重新开始一个预测流水。这样的做法可以在简单预测器准确率较高的情况下,省去复杂预测器的访问延迟。
下图是一个 SiFive P870 的设计,可以明显得看出具有 Cascading BP 的的设计。
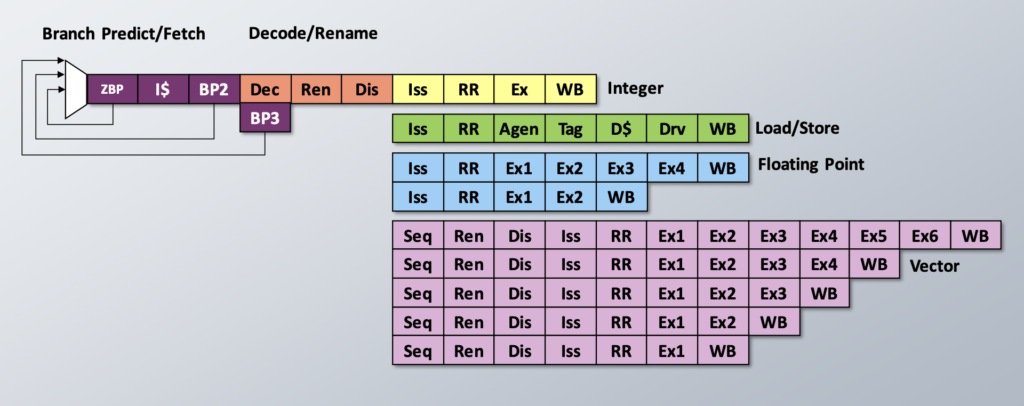
覆盖重定向的设计带来了新的问题——预测流水和取指流水,也即 ICache 流水,的速度不匹配。预测流水出现前端重定向的时候,ICache 可能仍能取指,ICache 出现缺失的时候,BP 就处于阻塞状态。为了避免相互影响,现代高性能处理器普遍采用了解耦合前端(或称为分离式前端),只有少量的处理器设计采用传统的设计。
下图是高通在 HPCA 2019 上发表的论文 Elastic Instruction Fetching 中的配图
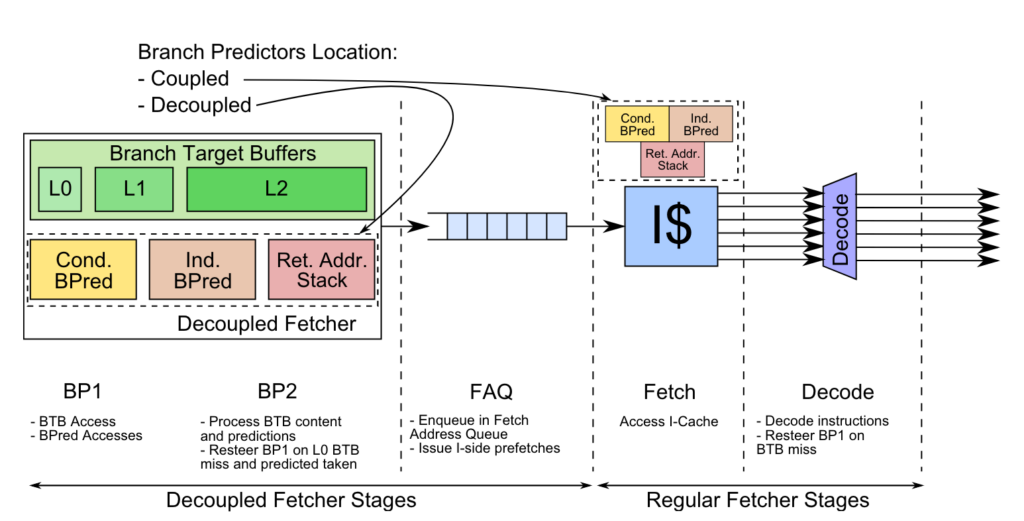
学术与产业落地
我曾经一度认为商业公司秘密发展了新的分支预测算法,而且不予公开,并且感到十分不高兴。

后来我很快认识到工业界中使用的分支预测算法非常的保守,甚至大部分的商业处理器都只使用了 TAGE 预测器或者 TAGE-L 等价的预测器。
香山处理器的分支预测器也从雁栖湖的 TAGE-SC-L 变成了南湖和昆明湖的 TAGE-SC,然后甚至正在考虑去掉 SC。
这样的情况可能和很多人的认识相悖,尤其是刚参加完龙芯杯或者一生一芯学习的同学。也和一些刚毕业的研究生或者长时间从事学术研究的人的认识有冲突。分支预测准确率对于高性能处理器的影响是非常巨大的,为什么这些在相同存储下能够取得更好预测准确率的算法没有被工业界采用?
接下来我们就讨论一下工业界对于分支预测算法更关注什么?
工业界关注什么?
首先,工业界和学术界的区别在哪里?学术界相信大家都很好理解,只要一个算法在相同的存储空间下能够取得更好的准确率,就可以认为这是一个更好的算法。但是在商业高性能处理器的设计中,还必须要考虑实际的延迟,以及性能、功耗、面积的平衡。
更新延迟
首先是一个非常明显的问题,部分学术界的研究也已经涉及到了,那就是在真实处理器中,分支预测器的更新只能在后端执行完毕以后才能拿到准确的分支执行情况。现代的预测算法都依赖分支的历史,如果历史不准确,将会极大地影响预测的准确率。然而下一条分支的预测开始时,上一条分支还远没有执行完毕,现代处理器中 in-flight 的分支数量普遍可达数十条。那么下一条分支如何拿到前一条分支的方向用于历史的计算?
目前普遍采用的做法是推测更新历史,也就是在预测后立即更新分支历史供下一条分支使用,然后在分支误预测发生时对历史进行恢复。这个做法能够较好的解决历史不及时的问题,但是 Pattern History Table(PHT)的更新依然可以是可以探讨的设计。是在分支执行完就更新?还是等到 commit 以后才更新?总体来说越早更新 warmup 越快,越晚更新更新得越准确。
推测更新历史的做法就引起了下一个问题——为什么现代处理器的分支历史都是全局历史?前文刚刚讨论了局部历史和全局历史对分支预测有不同的贡献,给任何预测器加入局部历史几乎都可以进一步提高预测准确率,那么为什么没有人用?只有部分处理器使用了专门的 Loop 预测器(Loop iteration count 就是一种特殊的局部历史)。这就涉及局部历史推测更新后的恢复困难问题。
历史维护
局部历史维护的困难可以参考 MICRO 2019’的论文 Towards the adoption of Local Branch Predictors in Modern Out-of-Order Superscalar Processors 。
因为全局历史整个处理器只需要维护一份(或少量几份用于推测更新-恢复用),一般都直接使用寄存器来存储全局历史。但是局部历史是需要按照分支来维护,即便是只维护部分活跃的分支,也需要较大的表,因此几乎必须使用 SRAM 来存储。
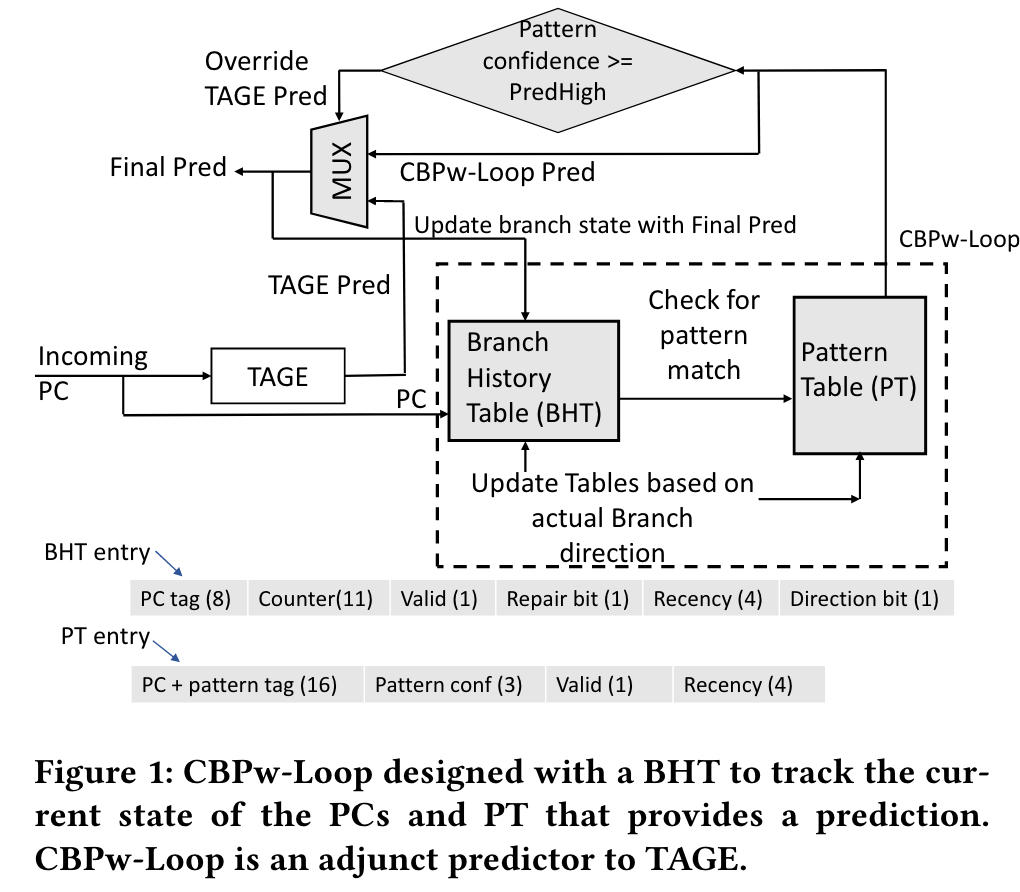
上图是按照分支预测锦标赛中软件实现的 Loop 预测器设计的对应硬件的框图,可以看到需要一个 Branch History Table(BHT)用于记录目前的循环计数。
使用 SRAM 存储带来的问题就是,恢复历史时无法在一拍内恢复或者甚至无法在短时间内恢复。目前已有的几种解决办法是
- 维护 in-flight queue,预测时同时查询 queue 获得新的历史,SRAM 内仅存储 commit 后的分支信息,不需要恢复 SRAM,对预测时序和功耗影响大。
- 维护 recover queue,SRAM 内推测更新历史,恢复时通过 walk queue 来恢复 SRAM 内的信息,对恢复速度要求高。
- 设计机制,让 SRAM 内历史不准确的时候不参与预测,可以较慢恢复 SRAM 内的信息。
更多设计细节的评估和对比可以参考上面的论文。
这种维护的困难使得局部历史在现代处理器的分支预测器中很少见到。
Path History
无论是哪一种分支历史,由于推测更新的维护方式,都必须先出现在 BTB 中,才能进入历史。然而,正常程序中会出现大量从不跳转的分支(如 debug 或错误处理),没有人愿意为了存储这些分支耗费多几倍的 BTB 存储开销。现代处理器普遍只有曾经跳转过的分支才会存储进入 BTB 中,这给维护 Branch History 带来了困难,如果有新分支突然 taken,那么它附近的分支由于历史的变化,基本需要重新 warmup。有的处理器为了让有限的历史寄存器放入更多有意义的信息,可能会对分支做进一步的过滤,只有 T/NT 均出现至少一次的分支才会进入历史,这样需要重新 warmup 的概率也就上升了。
因此工业界更倾向于使用 Path History。Path History就是将跳转的 Target 经过哈希计算进入历史中,这种历史天然地不受不跳转的分支影响。通过论文观察到 ARM 和 Intel 都使用了 Path History 来代替 Branch History。

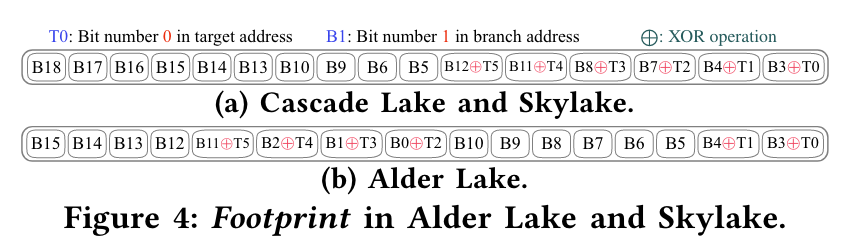

主频 & 预测延迟
如果说前面的几个方面只是增加了复杂分支预测算法落地的难度,那么预测延迟就是阻碍复杂算法落地的直接障碍。举一个例子,TAGE-SC-L 预测器中的 Statistical Corrector(SC)是为了纠正 TAGE 对于一些偏向性大的分支预测不好的部件,同时 SC 还可以作为 TAGE 的补充,如果 TAGE 由于哈希或者别的 corner case 出现失效,那么 SC 可以在一定程度上挽救问题。
但是 SC 需要使用 TAGE 的结果作为输入,还需要做所有表项的加法规约,因此在现代处理器的主频下,延迟比 TAGE 多1-2拍。这样多出来的延迟可能就把将存储分给 SC 的优势给抵消了,如果 SRAM 时序允许的话,给 TAGE 增加额外的 10% 的空间可能能取得更好的效果。SC 增加的延迟在学术上是欠评估的,因为 SC 提出的场景是分支预测锦标赛,该比赛并不要求模拟实际的预测延迟,因此复杂的预测算法更有可能因为合理的存储空间分配而获得更好的效果。
根据我的观察,SC 目前在大的商业处理器上应用很少,可能是加入这个部件增加的功耗、面积、验证成本等已经超过了它带来的误预测率降低的好处了。
Multi-branch ahead
根据统计,桌面应用的平均基本块长度约在5条指令附近(4-10),因此在设计宽译码、宽发射的高性能处理器时,如果每周期只预测一条分支,那么供指能力是不足的。现代高性能处理器普遍具备每周期预测两条指令的能力,但是根据设计能力和目标的不同,一般对两条指令的性质会有一些限制。最常见的是要求本周期的第一条指令不能跳转,这种限制大大降低了设计难度,因为在这样的限制下,两个基本块是连续的,每周期只会产生一个新的 PC,不需要做大量额外的设计就可以支持。
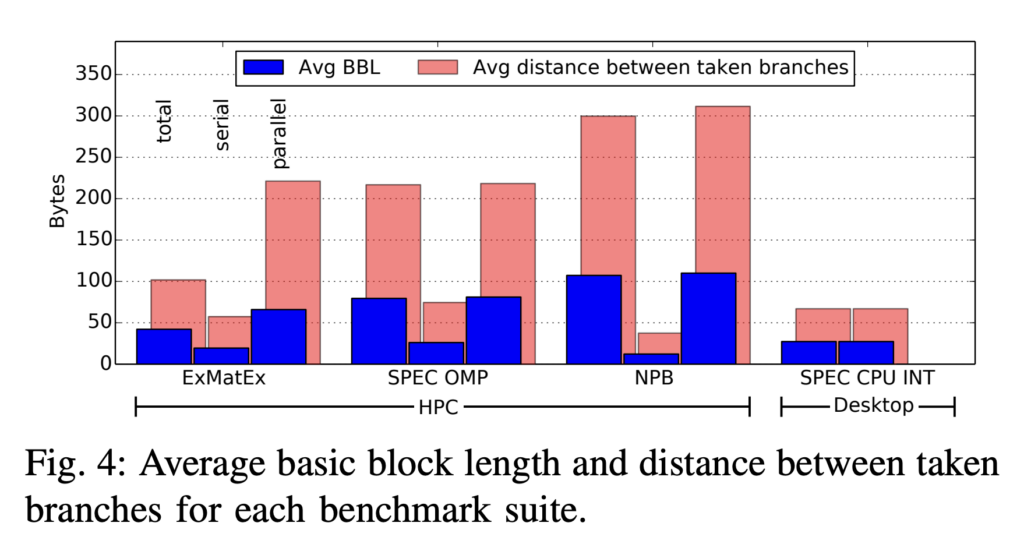
从上图中可以看到,基本上仅支持这种限制较严格的 2 Branch per cycle 就可以提升每周期的平均供指数量。香山处理器昆明湖目前也仅支持这种情况,实际在 SPEC CPU 2006 上可以做到平均每周期6-7条指令的供指能力。
近年来也有处理器能够支持 2-Taken per cycle的情况,如 ARM 和 Intel 的最新产品,但同时也有对两条分支的类型或者支持的数量做限制。
BTB设计
BTB 设计也是重要的一环,目前的设计方向有以下几个:
- 多级 BTB
- 下级 BTB 与 Cache 共用存储
- BTB 压缩
- L0 BTB / 快速预测器的设计
- L1 BTB 的类型
其中除了 L1 BTB 的类型,其他的都比较好理解。那么为什么需要单独讨论 L1 BTB 的类型呢?因为 L0 BTB 大多使用寄存器,排布灵活,L2 BTB 有压缩等设计,类型也可以灵活。唯独 L1 BTB 在预测的关键路径上,不能使用复杂排布,又需要足够大的容量,因此需要使用 SRAM,对读写有较为严格的限制。因此 L1 BTB 的表项设计和索引方式是前端设计中的重点,这里的设计也会大幅影响 TAGE 预测器和整个前端的设计。
今年的 MICRO 2023’恰好有一篇BTB的类似综述文的文章 Branch Target Buffer Organizations ,感兴趣的读者可以找来看看。其中有对 L1 BTB 的三种常见类型的描述和对比
- I-BTB:紧耦合前端,使用 ICache+预译码充当大容量 BTB。采用这样设计的有苹果和 SiFive。这种设计的优点是不需要为 BTB 使用额外的存储,缺点是紧耦合前端供指能力稍弱,另外 ICache 存储分支的效率是较低的,超过 ICache 容量之后,将无法使用分支信息指导指令预取。
- R-BTB:使用减少的空间来存储一定范围内的分支(如 64B),在范围内支持一定数量(如8条)分支,BTB 使用对齐的 PC 索引,通过 offset 来确定具体的分支。优点是使用独立的 BTB 和解耦前端后,前端对分支的处理能力大幅加强,IBM 的 z15 处理器设计中,BTB 的总容量甚至可以 cover L2 Cache 的大小。缺点是当分支密度高的时候无法全部覆盖。
- B-BTB:每个表项内存储一个基本块(或一个 Fetch Stream)的信息(下称取指块),取指块内可以有多个分支,有最长的取指块大小,使用 PC 低位索引,高位做 Tag。这种做法解决了 R-BTB 对分支密度的限制,能够处理绝大多数的情况。缺点是一个分支可能出现在多个表项内,会浪费一定的存储空间。
香山南湖和昆明湖的设计都是使用 B-BTB 的设计,取指块中允许两个 Branch Slot,第一个仅允许条件分支,第二个允许所有类型的分支。然后预测时如果第一个分支预测不跳转,那么可以按照离第二个分支的距离来供指。
功耗
功耗这一块其实我知之甚少,因为香山还没有开始做低功耗设计(狗头保命),但其实有许多大方向是低功耗设计共性的。首先,因为分支具有难度的差别,还有类型的差别,复杂的预测器和 ITTAGE 这类的间接跳转预测器是没有必要每个PC每个周期都访问的。另外 TAGE 中,每个历史表对于程序片段中的有用程度也是不一样的,所以通过统计的方法,是可以在保留大部分性能的情况下省去很多 SRAM 的功耗。
另外 SRAM 与 SRAM 天差地别,如果设计时给 SRAM 留了时序裕度,选用稍慢的 SRAM 可能可以大幅降低功耗。
一定要预测吗?
最后想谈一下从体系结构的角度,分支一定要预测吗?近年来分支预测算法发展陷入停滞,原因是 TAGE 预测器的算法已经足够优秀,能够在存储耗尽之前充分地挖掘一条分支的“可预测性”,后续的改进也基本针对 corner case 的优化和存储替换算法、置信度等的一些小优化。
那么,剩下的分支误预测怎么办,还有办法吗?此时就需要跳出固有的思维框架,不再仅思考纯硬件的做法,就会发现有新的天地。实际计算机的设计是一个系统工程,需要每一层紧密配合才能达到最好的性能。此处我们介绍两个已经实用的方法,有没有别的新的方法留待读者探究。
谓词化指令
谓词化指令其实就是赫赫有名的条件执行指令,例如 cmov 指令就是著名的谓词化指令。设计这种指令的初衷是很多难预测的分支是和程序数据紧密相关的,甚至直接依赖于数据,那么如果将这些分支转化为 cmov 或类似的条件转送/执行指令,就可以只出现数据流的变化,而不出现控制流的变化。
谓词化指令在 x86 体系和 ARM 体系中都有大量的使用,RISC-V 在 2023 年也通过了 Zicond 扩展。
软硬结合
这里讲的软硬结合大致是指 hint 类型的指令,苹果已有专利说明其设计的处理器中,有针对 macOS/iOS 进程间调用返回的长跳转做 hint 和指令预取的优化,具体的优化只能翻专利了。
结语
其实还有更多的具体设计细节,这里由于篇幅考虑(实际是我偷懒)就不详细展开了,在这里提一个列表共大家思考
- 单端口 SRAM 的读写冲突处理
- 预测器 ctr 降低更新延迟的影响,加快 warmup 的方法
- B-BTB 中的多个分支对于方向预测器容量需求不对称的问题
- 预测器中 SRAM 分 bank 的方法
- TAGE 折叠历史的维护方法
- 各种预测器和 BTB 的索引哈希
现在看了这么多设计考虑,你还认为预测准确率是分支预测器唯一的评价指标吗?
参考文献
- The Alpha 21264 microprocessor
- A case for (partially) TAgged GEometric history length branch prediction
- Elastic Instruction Fetching
- Towards the adoption of Local Branch Predictors in Modern Out-of-Order Superscalar Processors
- Branch Target Buffer Organizations
- Half&Half: Demystifying Intel’s Directional Branch Predictors for Fast, Secure Partitioned Execution
- Re-establishing Fetch-Directed Instruction Prefetching: An Industry Perspective
- Rebalancing the core front-end through HPC code analysis
- 香山处理器分支预测文档

写的真的很好,加上这么有品味的blog页面,很赞