预计阅读时间: 8 分钟
本文基于的应用场景是作者个人维护十数台可用性要求不是很高的非生产环i8境服务器(个人博客,团队git服务器等)。
那么这样的应用场景要求选用的系统尽量满足一下特性:
- 免费/开源/便宜
- 快速
- 轻量
- 可扩展性强
目前作者接触到的服务器监控系统大概有那么几个,全部都基于开源软件。传统老牌监控系统Zabbix和Nagios、基于Prometheus的监控系统解决方案和基于InfluxDB的解决方案。对比了这些方案后,作者选出了一种最适合的系统,只想看结论的同学请直接翻到文末。
Zabbix 和 Nagios
Zabbix
Zabbix 作为老牌的企业级服务器监控系统,功能非常强大。
官方介绍有许多功能,包括:
- 几乎所有协议和数据结构的数据来源(包括SNMP, IPMI等基础设施管理协议)
- 极其丰富的配置项
- 丰富的API控制
- 完全的用户权限和认证系统,提供PAM支持
- 一站式的解决方案,可提供图表绘制、日志审查、报警等所有可能用到的健康度监控工具
- 自动发现设备和数据来源
- 自动化维护和检查
- 可自定义的前端样式
功能强大的同时也相应的会带来重量级的问题,官方文档给出的要求是100个监控项的数量级至少需要128MB内存和256M硬盘来安装,实际使用中一般需要1GB内存和100G左右的硬盘来保证比较良好的可用性。
不过这样的问题仅仅是对于小规模应用场景来说的,真正企业级的应用中zabbix还是属于相当轻量的,也是当之无愧的首选。
Zabbix虽然提供了高度的可定制性和多到令人厌烦的配置选项,但是作为一站式方案的系统,系统耦合度很高,不利于大型、实力强的企业做二次开发和组件替换。
我个人在一年多前使用过一会zabbix,安装并不困难,甚至比Mysql的安装配置都简单,但是完成后监控配置十分负复杂,对于两位数的机器没有必要如此细致的配置。Zabbix适用于中型企业专门雇有2-3人运维团队的场景,对于个人非专职而言全套系统一一配置下来还是显得过于繁杂。
当然,Zabbix仍然不失为一个优秀的监控系统。
Nagios
Nagios相比于Zabbix似乎更为的重量级,至少需要1GB的内存和8GB的硬盘来完成一次完整的安装。
与Zabbix提供的一体式解决方案不同,Nagios的系统更加组件化,提供给大型企业更大的自定义空间,组件间耦合度较Zabbix低。
我自己未安装使用过Nagios,因此不作过多评价。
总体而言,Zabbix和Nagios都是企业级的监控方案,主要面对企业用户开发,也适用于企业的应用场景。但是其部署和配置的过程十分烦琐,不符合我们“快速”的宗旨,所以不是特别合适。
第三方监控服务
第三方提供的监控服务从简单到复杂,从免费到收费,几乎应有尽有,只要你肯出钱,没有找不到的解决方案。如果你比较不愿意自己动手搭建,或者不愿意雇佣专职运维,这样的外包服务在公司规模较小的情况下还是很常见的。
当然,这很难满足我们“免费/便宜”原则,可扩展性相比于前文的两个企业解决方案更差。所以第三方的监控服务更适用于希望能够直接外包运维的非互联网甚至非技术型企业。
基于Prometheus
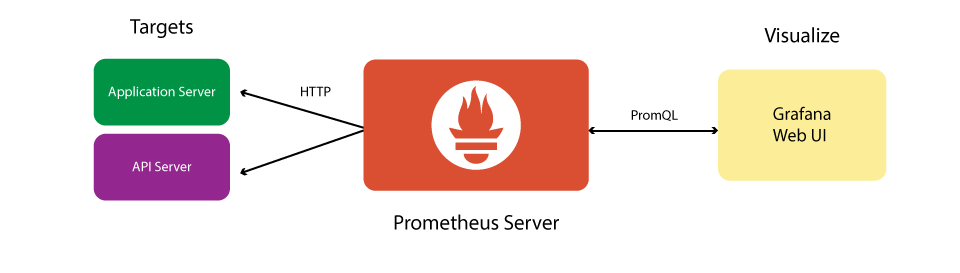
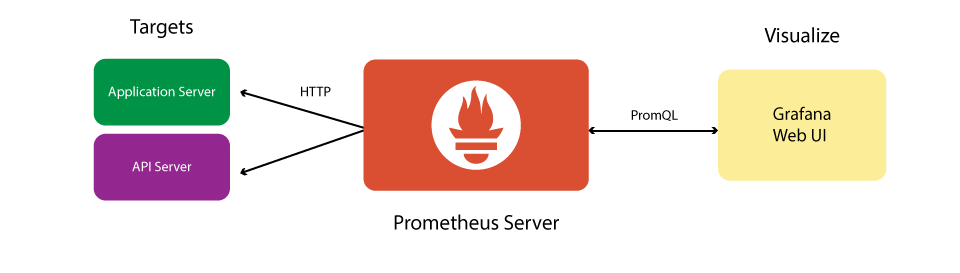
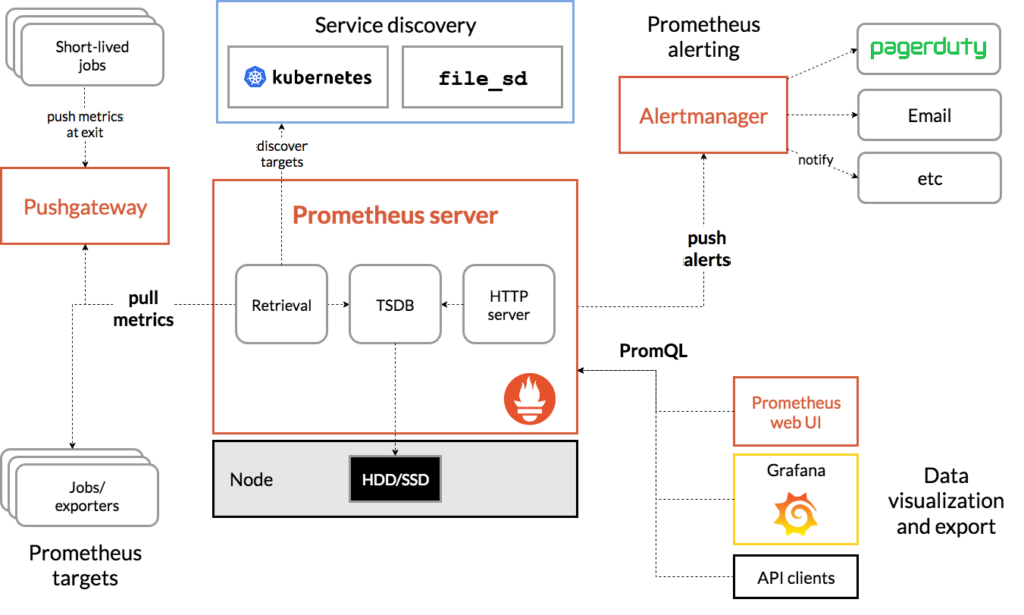
基于Prometheus的监控系统架构一般如下
或是这个简化版
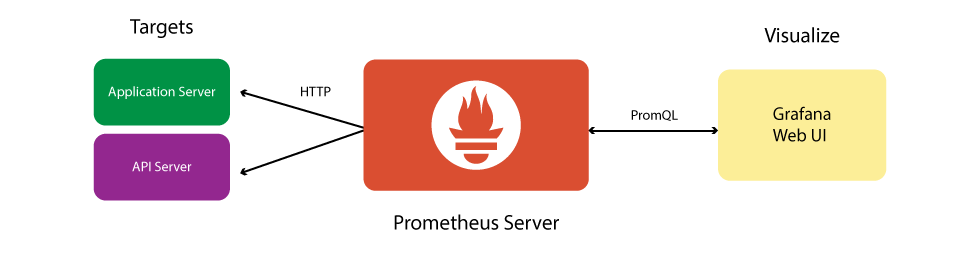
Prometheus本身是一个时序数据库套件,提供了监控系统中的数据收集服务端和数据库的角色(也就是上图中的Prometheus Server部分),官方还提供了报警管理的模块(上图中Alert Manager),因此我们还额外需要数据展示和数据收集的客户端(上图中Prometheus Target和Data Visualization)。
这一额外的部分有很多的选择。对于Target 可以有各种Exporter 在官方页面有列举。甚至任何支持metric格式输出的数据收集端,比如nNetdata、statsd等。数据可视化我们一般会选择Grafana,当然其它如Grafite等只要支持PromQL查询的都可以。
此套解决方案我不久前部署过,它的优点很多,包括了全部开源,模块化,可扩展性强,可以docker部署,部署非常简单。它也较为的轻量,完全部署仅需30M左右的内存。当然硬盘占用是跟随着数据量的增大而增大的,无数据情况下大约占用200-300M的硬盘空间。
基于InfluxDB
TICK栈
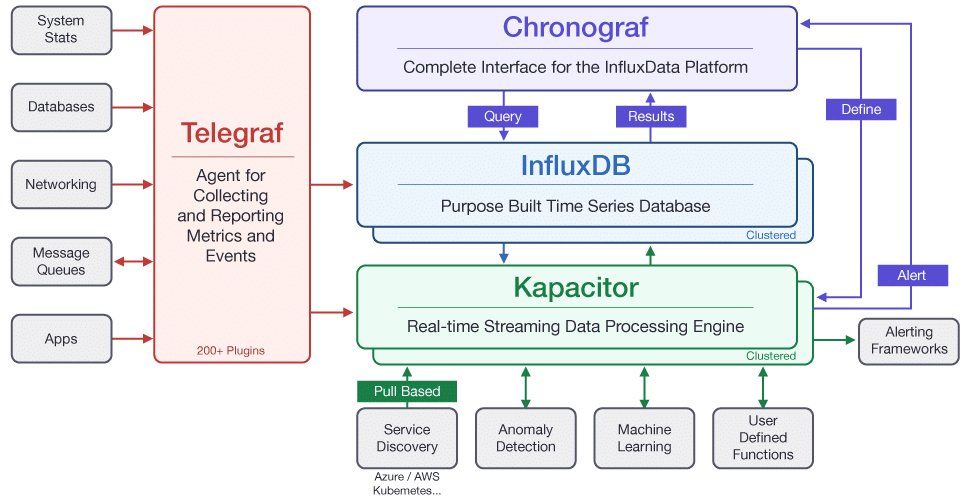
TICK是InfluxData官方主推的监控技术栈。
Telegraf+InfluxDB+Chronograf+Kapacitor,将整套系统拆分成为四个模块,模块化特征明显。因此任意支持InfluxDB读写的数据收集或者监控模块都可以使用。
TICK当然也可以使用docker-compose管理,无论是部署还是迁移都很方便。
Telegraf提供了近百种不同的系统健康信息收集,若是还不够用也可以自己写插件,具有非常强大的可扩展性。
Chronograf集成了Kapacitor的管理功能、InfluxDB的直接查询和Dashboard数据展示功能。不仅如此,前端设计也非常养眼。
同样地,TICK栈也拥有与Prometheus媲美的优势——轻量、可扩展性强等等。下面我们就会讲到使用Grafana扩展数据可视化的功能。
TICGK栈
虽然官方开发的Chronograf已经拥有精美的图表可以显示,但是论数据可视化,Grafana是难以逾越的强大开源方案。因此我们在TICK中加入Grafana,成为TICGK栈,这样一来几乎所有的优点都被涵盖了。虽然五个容器会带来磁盘和内存占用增大的影响,但是对比于异常强大的功能和简单易用的界面,这个技术栈完全适合作者的应用场景。也许在高并发和大数据量的场景下TICGK栈表现会下降,但是作为个人使用,担心并发无疑是杞人忧天。
毫无疑问,最后作者选择部署的就是TICGK栈,使用docker-compose管理(就几个容器没必要k8s吧)。目前状况良好,总体内存占用60M左右,设置了5s的时间粒度,15天周期后预计的硬盘使用是4GB,还是可以接受的。存在一个现象就是5s的粒度会带来Telegraf内存占用问题,开了很多Buffer,但是事实上Buffer什么的并不真正影响啊。
看完作者的选型,你有什么想法呢?欢迎在评论区交流。
才疏学浅,若有错漏,也恳请指正。
敬请期待下一篇——服务器性能监控(二)
